
Auteur: Ryan Watts, Alexandra Ma et Nic Dias
Les journalistes cherchent désormais à débusquer les fausses informations mais on lit beaucoup moins de choses sur les initiatives prises pour suivre ce dont les internautes parlent sur les médias sociaux, pour détecter la localisation géographique et la vitesse à laquelle les fausses informations circulent. Différents outils peuvent pourtant 1/ aider les journalistes à suivre les conversations en ligne en temps réel et 2/ être intégrés dans les procédures mises en place pour vérifier l’exactitude des faits et la véracité des informations.
Durant le déroulement du projet Full Fact First Draft lors de la campagne des élections législatives en Grande Bretagne, nous avons suivi une grande quantité d’échanges en ligne pendant trente trois jours. Nous proposons ici une brève description de nos opérations au jour le jour pour proposer une méthodologie aux journalistes qui doivent réagir rapidement à des conversations en ligne liés à l’actualité et juguler un flot de désinformations.
Nos livrables
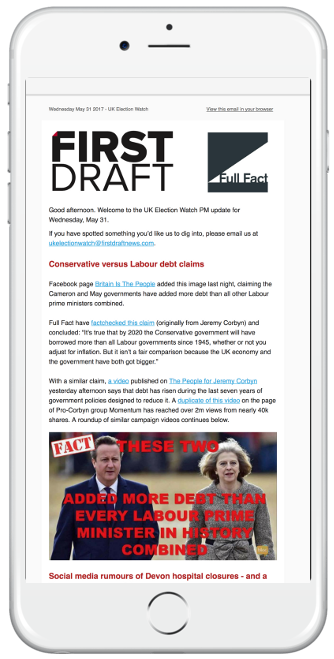
Dans le cadre du projet, les abonnés ont reçu un email deux fois par jour.
Nous avons produit deux lettres d’information quotidiennes, envoyées aux partenaires de notre rédaction chaque matin et chaque après-midi.
La lettre d’information du matin avait pour but de donner à nos partenaires des indications sur les conversations en cours liées à l’actualité et pour signaler les contenus sur les réseaux sociaux dont nous avions remarqué qu’ils gagnaient en popularité.
La lettre d’information de l’après-midi était principalement consacrée à la vérification des faits, à la clarification sur les publications mensongères sur les réseaux sociaux, au profilage des tendances en cours pouvant avoir des résonnances politiques, et à l’explication des différences entre ce que les rédactions des médias traditionnels couvraient et ce dont les communautés en ligne parlaient.
Les préparatifs
Avant d’envoyer notre première lettre d’information, nous avons consacré une semaine à compiler un recueil d’informations ‘fabriquées’ sur le Royaume-Uni, des sites satiriques aux blogs ultra partisans, en passant par les pages et groupes Facebook consacrés à la politique, aux fils de conversation sur Reddit et aux mots-clics sur Twitter qui, selon nous, devaient être suivis à l’aide d’outils mesurant la popularité des posts comme Trendolizer, CrowdTangle et Spike de NewsWhip. Ces listes ont été régulièrement mises à jour durant la campagne électorale. Le 8 juin, jour de l’élection, nous suivions 402 sources et sujets et avions collectés plus de 34 millions de tweets et 220 000 posts sur Facebook dans nos serveurs.
Trendolizer nous a aidés à repérer des contenu devenant viraux sur toutes les plateformes de réseaux sociaux en temps réel. L’outil nous a permis de mettre en place des recherches en utilisant une variété de paramètres, afin de trouver les posts pertinents et qui marchaient bien. Nous avons constitué une liste de mots-clés liés à l’élection pour les recherches et nous avons mis en place de multiples ‘colonnes’, à la manière de l’outil Tweetdeck, qui illustraient quel impact avaient les posts selon différents paramètres, tel que, par exemple, le nombre de partages durant une période de 24 heures. Lorsque nous avons introduit de nouveaux thèmes, nous avons ajouté des ‘colonnes’ distinctes pour ces sujets.
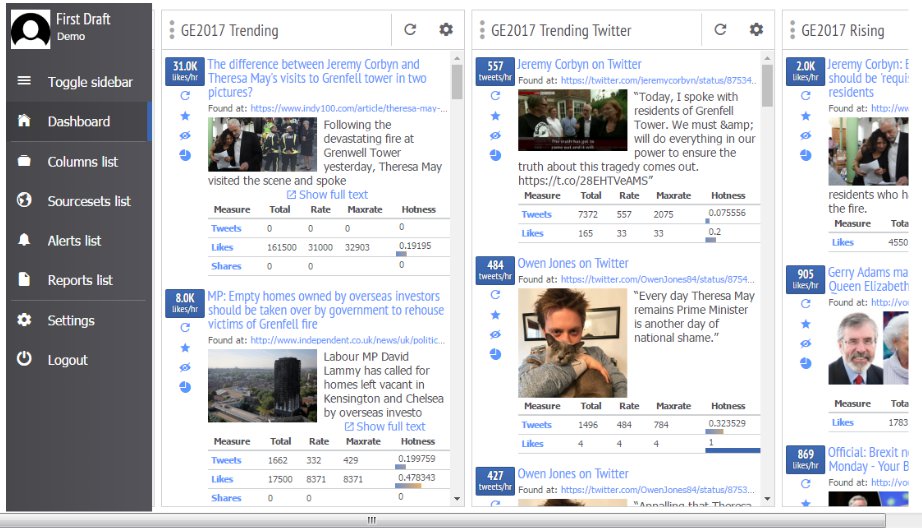
Capture d’écran de notre tableau de bord sur l’outil Trendolizer.
CrowdTangle, un outil de Facebook, nous a aidés à trouver des publications qui sur-performaient sur des pages Facebook particulières (par exemple, qui généraient plus d’interactivité que d’ordinaire sur cette page). Pour des statistiques plus détaillées sur les posts sur les réseaux sociaux ou les articles, nous avons choisi Spike de Newswhip, qui fait ressortir les articles les plus lus et fournit des projections fiables sur le taux futur et probable de partage.
Pour suivre les méta conversations sur Twitter, faisant appel à de multiples mots-clics, nous avons utilisé Trendsmap, qui enregistre la croissance et la dispersion géographique de l’utilisation des mots-clics et des mots-clés sur Twitter. Cet outil nous a également été utile pour identifier les tweets à l’origine de tendances, et fournir des estimations brutes du minimum de comptes ‘robotisés’ qui avaient partagé ces tweets.
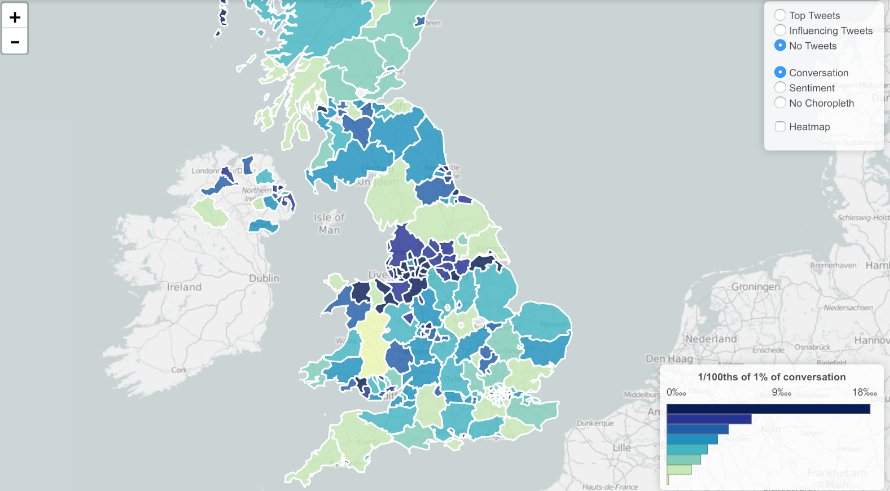
Trendsmap nous a permis de visualiser où des conversations précises avaient lieu géographiquement.
Nous n’avons pas pour autant négligé les sources traditionnelles d’informations. Chaque jour, nous avons suivi les Unes des journaux et écouté les grandes émissions d’information du matin (comme le programme Today, l’émission de Steve Allen sur LBC et Wake up to Money sur la BBC Radio 5) pour comparer la couverture des médias traditionnels et les conversations sur les réseaux sociaux.
Pour ‘aspirer’ les données des posts publics sur Facebook et Twitter, nous avons dédié un serveur à chacun de ces deux réseaux sociaux et avons commencé à collecter des données sur ces posts un mois avant le jour de l’élection.**
Notre serveur dédié à Facebook nous a permis d’identifier où et quand les pages et les groupes Facebook gravitaient autour de liens et sujets spécifiques. De plus, le serveur nous a permis d’analyser les différences de thématiques dans les conversations qui avaient lieu à différents ‘points’ du spectre politique. De façon plus générale, ces données ont donné de la versatilité à nos analyses quand besoin était.
Notre serveur dédié à Twitter a archivé de façon brute les tweets comprenant au moins un mot-clic ou nom de domaine préalablement identifiés. Ce qui s’est révélé pratique pour comparer la popularité de différents noms de domaine et mots-clics, ainsi que pour évaluer les rôles que les producteurs de contenus jouaient dans les Tendances. Notre champ d’exploration s’est régulièrement élargi en recherchant les nouveaux mots-clics dans notre base de données.
Ce qu’il faut retenir
1) Les statistiques sur la performance d’un post sur les réseaux sociaux, et non sur son contenu uniquement, peuvent être une source d’informations utiles pour les vérificateurs d’informations, les ‘fact checkers’. Au lieu de nous contenter d’affirmer qu’une déclaration était fausse, nous avons été en mesure d’évaluer l’importance d’un post en particulier dans un schéma ou une tendance plus large. Cet aspect est devenu d’une grande importance étant donné qu’il y a presque toujours eu trop de données à couvrir. Considérer la multitude de posts sur les réseaux sociaux avec une perspective déjà formée par les données sur le post nous a permis de fournir des analyses à valeur ajoutée aux partenaires de notre rédaction. Un exemple : quand une page Facebook nationaliste a posté une vidéo mensongère sur un attentat supposément commis par un réfugié, savoir en amont que ce contenu correspondait à une tendance de cette page à publier des posts similaires et produisait une échelle attendue de réactions nous a permis de juger qu’il n’était pas nécessaire de lui accorder trop d’attention.
2) La nature ultra rapide et débordante du travail de fact checking et de vérifications quotidiennes signifie que la vitesse est essentielle en matière d’outils analytiques. A noter : nos serveurs de récolte et stockage de données nous ont permis de les analyser d’une façon qui n’auraient pas été possible autrement et ils nous ont permis d’étayer plusieurs de nos articles. Mais comme les outils très maniables pour l’utilisateur tels que Trendsmap proposent une grande variété de paramètrages, il était plus efficace de les utiliser comme premier port d’attache, avant d’avoir recours à nos serveurs.
3) Avant tout, notre projet a fait ressortir qu’il est important de suivre les grandes tendances sur les réseaux sociaux et les schemas répétitifs repérés, ainsi que les posts et contenus uniques, alors que les salles de rédaction ont une tendance à figer. En identifiant des conversations en ligne plus larges, nous avons pu travailler sur les sujets que les électeurs actifs en ligne trouvaient les plus importants, comme le ‘vote tactique’, l’inscription sur les listes électorales et les problèmes sociaux – et non pas les négociations du Brexit, par exemple.
Appendice
* Nous avons volontairement voulu nous en tenir aux sujets suivants : Brexit, changement climatique, immigration, santé, défense, police et maintien de l’ordre, retraites, éducation. Après le commentaire de la Premier ministre Theresa May sur la chasse au renard, nous avons décidé d’ajouter le sujet de la chasse à nos thèmes. C’est ainsi que nous avons découvert que les conversations sur la chasse au renard et la cruauté envers les animaux ont perduré, même quand Theresa May a cessé de parler de sa position sur la chasse au renard.
** Pour ‘aspirer’ des posts des pages et groupes Facebook publics, nous avons adapté le code informatique écrit par Max Woolf. Nous avons conservé nos listes de pages et groupes à explorer par le code sur Google Sheets, qui a aussi fait office de ‘file d’attente’ pour nos scripts.
La possiblité de partager les fichiers Excel de Google Sheets a aussi permis aux membres de l’équipe d’ajouter des pages et des groupes à notre cycle de récoltes de données, dès qu’ils devenaient disponibles. Les posts récents étaient aspirés à nouveau à chaque heure, pour jauger la croissance des posts uniques. Un troisième script (programmé, là encore, à une fréquence horaire) préparait les données pour l’exportation sous forme de fichier compressé Zip téléchargeables à partir d’un simple serveur HTTP. Ceci a permis aux membres de l’équipe de télécharger des données Facebook récentes de façon autonome sans avoir à transférer les fichiers via le terminal.
Nous avons installé Social Feed Manager (SFM) sur un deuxième serveur, pour pouvoir collecter les tweets : Le SFM (Social Feed Manager) a, là encore, permis à ceux qui ne sont pas développeurs de pouvoir lancer, modifier et exporter des séries de données. Notre méthode primaire de récolte de données a été l’API de recherche, lancée à chaque heure. Cette méthode a été préférée à l’API Streaming, parce qu’elle nous permet d’éviter de perdre des données durant les changements de requêtes ou les problèmes de serveurs. Les clés API ont été générées par l’administrateur du serveur sur la base des besoins exprimés mais les journalistes ont aussi été autorisés à générer eux-mêmes des clés.
Informations sur les serveurs
Facebook – 8GB de RAM, 4 CPU, Disque 60GB SSD
Twitter – 16GB de RAM, 8 CPU, Disque 160GB SSD
Facebook et Google News Lab ont soutenu First Draft et Full Fact dans leur collaboration avec les rédactions des grands médias pour lutter contre les rumeurs et la désinformation répandues sur les réseaux sociaux durant les élections législatives au Royaume-Uni.
Ceci est le deuxième article de blog d’une série consacrée au projet Full Fact-First Draft à l’occasion des élections législatives au Royaume-Uni. Lire le premier post de blog sur les élections législatives au Royaume-Uni : “Ce que nous avons appris en travaillant avec Full Fact”


