
Por: Ryan Watts, Alexandra Ma y Nic Dias
Mientras los periodistas están ahora dedicados a desmentir la desinformación, es mucho menos lo que se escribe sobre cómo dar seguimiento a lo que se discute en medios sociales, y dónde y qué tan rápidamente se difunde la información inexacta. Aun así, hay varias herramientas disponibles que pueden (1) ayudar a los periodistas a rastrear conversaciones en línea en tiempo real y (2) ser incorporadas en flujos de trabajo para verificar datos y verificar noticias.
Como parte del proyecto electoral de Full Fact/First Draft sobre las elecciones británicas, estuvimos al tanto de una gran cantidad de conversaciones en línea durante 33 días. Acá ofrecemos una breve descripción de nuestras operaciones cotidianas para que sirvan como plan de acción para periodistas que busquen responder rápidamente a conversaciones de interés y para detener el flujo de información errónea.
Los productos
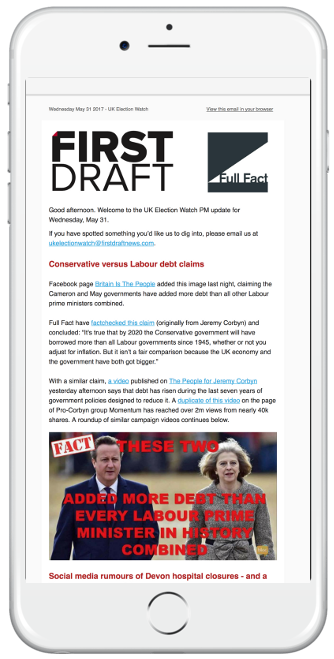
El proyecto envió correos electrónicos dos veces al día a los suscriptores.
Elaboramos dos boletines diarios que enviamos todas las mañanas y todas las tardes.
El boletín de las mañanas servía para dar a nuestros asociados un panorama de las conversaciones de interés y contenido social que vemos que cobra impulso.
El boletín de las tardes se centraba mayormente en verificar datos o aclarar publicaciones engañosas en publicaciones de medios sociales, trazar perfiles de tendencias en curso con posibles consecuencias políticas y destacar las diferencias entre lo que informan las salas de redacción convencionales y lo que analizan las comunidades en línea.
Los montajes
Antes de enviar nuestro primer boletín, dedicamos una semana a recopilar una lista de sitios web de noticias fabricadas y satíricos, blogs hiperpartidarios, páginas y grupos de Facebook con tendencia política, subreddits y etiqueta de Twitter dedicados al Reino Unido a los que pensamos que valía la pena rastrear con ayuda de servicios de tendencias sociales como Trendolizer, CrowdTangle y Spike de NewsWhip. Estas listas aumentaron frecuentemente durante las elecciones. Para el 8 de junio, ya rastreábamos 402 fuentes y temas, y habíamos recogido más de 34 millones de tuits y 220,000 publicaciones de Facebook con nuestros servidores.
Trendolizer nos ayudó a descubrir contenido viral en todas las plataformas sociales en tiempo real. La herramienta nos permitió configurar búsquedas con diversos parámetros para encontrar publicaciones relevantes a las que les iba bien. Agregamos una lista de términos de búsqueda relacionados con las elecciones y preparamos muchas “columnas” de estilo Tweetdeck que analizaban qué tan bien les iba a las publicaciones según diferentes parámetros, como las veces que se compartía en un periodo de 24 horas. A medida que ahondábamos en asuntos nuevos, agregábamos columnas separadas para estos temas.
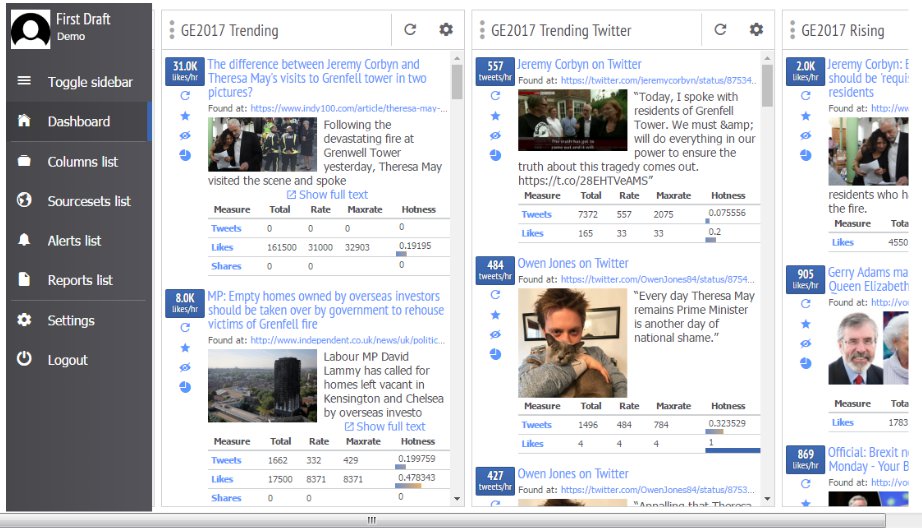
Vista de nuestro tablero Trendolizer.
CrowdTangle de Facebook nos ayudó a encontrar publicaciones a las que les iba muy bien en páginas de Facebook en particular (por ejemplo, que atraían más interacciones de lo normal para esa página). Para estadísticas más detalladas en publicaciones en medios sociales o artículos, confiamos en Newswhip Spike, que destaca artículos con buenos resultados y ofrece proyecciones confiables de sus futuros índices de difusión.
Para observar conversaciones más amplias en Twitter que abarcan muchas etiquetas, o hashtags, usamos Trendsmap, que registra el crecimiento y dispersión geográfica del uso de etiquetas y palabras claves en Twitter. La herramienta también fue útil para identificar tuits que impulsan tendencias, y para tener estimados mínimos de cuántas cuentas automatizadas difundieron estos tuits.
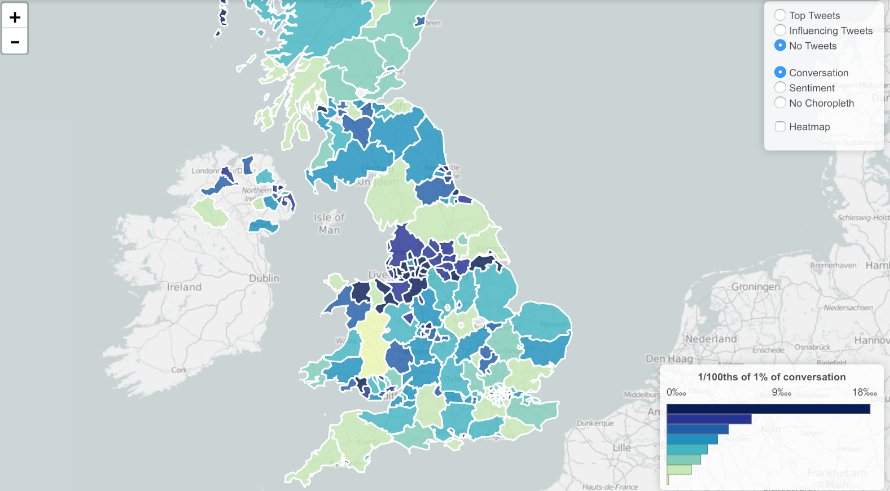
Trendsmap nos ayudó a visualizar dónde se llevaban a cabo conversaciones específicas.
Tampoco dejamos de lado las fuentes de noticias tradicionales. Todos los días, dimos seguimiento a portadas y sintonizamos programas matutinos de radio (como Today programme, Steve Allen en LBC y Wake Up to Money de BBC Radio 5) para comparar la cobertura de los medios convencionales con conversaciones en medios sociales.
Para extraer información pública de publicaciones de Facebook y Twitter, configuramos un servidor para cada red social y empezamos a recopilar información un mes antes del día de las elecciones.**
Nuestro servidor de Facebook nos permitió identificar dónde y cuándo páginas y grupos giraron en torno a vínculos y temas particulares. Además, el servidor nos permitió examinar diferencias de actualidad en conversaciones que hay en diferentes puntos del espectro político. De manera más general, la información nos brindó versatilidad en nuestros análisis cuando se necesitaba.
Nuestro servidor de Twitter archivaba holísticamente los tuits, incluida al menos una de las etiquetas o dominio que habíamos identificado. Fueron muy útiles para observar la relativa popularidad de diferentes dominios y etiquetas, y también para evaluar qué rol tenían los productores de contenido en las tendencias. Nuestra red de recopilación se expandía frecuentemente mediante con la revisión de nuevas etiquetas en nuestro conjunto de datos.
Lo importante
1) La estadística del desempeño de una publicación en un medio social, antes que solamente su desempeño, podría ser una fuente de información práctica para los verificadores de información. Más allá de decir si una declaración era falsa, pudimos ofrecer una evaluación de lo importante que sería una publicación en particular en un patrón o una tendencia mayor. Esto se volvió crucial, pues casi no había demasiado que informar. Ver la multitud de publicaciones de medios sociales desde un punto de vista informado nos permitió brindar análisis con valor agregado de nuestras salas de redacción asociadas. Por ejemplo, cuando una página nacionalista de Facebook publicó un video engañoso de un supuesto ataque hecho por un refugiado, saber que la publicación encajaba en una tendencia de publicaciones similares de esa página, con una escala de reacción similar, quería decir que sabíamos que no debíamos darle mucha atención a la publicación.
2) El abundante trabajo acelerado de la verificación de datos y la consultoría diaria significaba que, hasta donde llegan las herramientas de analíticas, la velocidad era clave. Notablemente, nuestros servidores de recopilación nos permitieron analizar la información de otras maneras que no hubiéramos podido, y apoyó varias de nuestras historias. Pero dada la escala de características que brindan las herramientas fáciles de usar como Trendsmap, fue más eficiente usarlas como la primera escala de lo que fue usar nuestros servidores.
3) Sobre todo, nuestro proyecto subraya la importancia de dar seguimiento a tendencias y patrones de medios sociales en general, y también de historias y publicaciones individuales, donde las salas de redacción tienden a fijar la atención. Escogiendo conversaciones más grandes, pudimos enfocarnos en temas que les importaban más a nuestros votantes en línea, como voto táctico, registro de votantes y problemas sociales — más que las negociaciones de Brexit, por ejemplo.
Apéndice
* Específicamente, queríamos enfocarnos en los siguientes temas: Brexit, cambio climático, inmigración, cuidados de salud, defensa, policía y aplicación de la ley, pensiones y educación. Después del comentario de caza del zorro de Theresa May, decidimos agregar el tema de cacería animal a la mezcla — así fue que encontramos que las conversaciones sobre caza del zorro y crueldad animal se mantuvieron, incluso después de que Theresa May dejó de mencionar su postura sobre la caza del zorro.
** Para reunir publicaciones de páginas y grupos públicos de Facebook, adaptamos textos de Max Woolf. Mantuvimos nuestras listas de páginas y grupos para que se recogieron en los textos de Google Sheets, lo que también sirvió como una línea de espera de tareas para nuestros textos. La naturaleza de Google Sheets, documentos que se pueden compartir, permitió que los miembros del equipo agregaran páginas y grupos a nuestro ciclo de recopilación cuando estuvieran disponibles. Publicaciones recientes fueron vueltas a recopilar a cada hora, para que pudiéramos rastrear el crecimiento de publicaciones individuales. Un tercer texto preparó (también cada hora) la información para exportarla como un archivo Zip, que se podía descargar desde un simple servidor HTTP. Este permitió a los miembros del equipo descargar información actualizada de Facebook independientemente, sin tener que transferir archivos a través del terminal.
Armamos un Administrador de Fuente Social (SFM) en un segundo servidor para recopilar tuits. SFM de nuevo permitió a no programadores iniciar, cambiar y exportar recopilaciones de información. Nuestro método principal de recopilación fue Search API, al que recurrió cada hora. Se eligió este método antes que Streaming API porque impedía que se perdiera información durante cambios de consultas o problemas en el servidor. Las claves de API las generaba el administrador del servidor de acuerdo a las necesidades, pero también se permitía a los propios periodistas generar claves.
Detalles del servidor:
Facebook – 8GB of RAM, 4 CPUs, 60GB SSD Disk
Twitter – 16GB of RAM, 8 CPUs, 160GB SSD Disk
Facebook y Google News Lab apoyaron a First Draft y Full Fact para trabajar en grandes salas de redacción para abordar difusión de rumores e información errónea durante las elecciones generales del Reino Unido.
Esta es la segunda de una serie de publicaciones de blog sobre el proyecto de Full Fact-First Draft para las elecciones británicas. La primera publicación sobre las elecciones británicas fue: Lo aprendimos trabajando con Full Fact


