
This recipe is the seventh in our Digital Investigations Recipe Series, a collaboration between the Public Data Lab, Digital Methods Initiative, Open Intelligence Lab and First Draft. It is designed to lift the lid on advanced social media analysis.
Introduction
If you are monitoring, researching or investigating mis- and disinformation, you will certainly come across memes. Those bite-sized images overlaid with text, at times innocuous and playful, can also be powerful tools in the “information warfare” operations of governments and bad actors around the world. Even the most trivial-seeming memes can become potent weapons to divide opinion and sow political discord.
Social media platforms may be improving their ability to automate the detection of misleading text-based content, but artificial intelligence still has a long way to go before it can seamlessly parse the images, text and, importantly, cultural context that make memes such a potent form of information. And memes are now becoming more popular, their spread facilitated by easily accessible photo-editing tools such as those on your phone.
So how can journalists and researchers surface memes and imagery related to particular topics, such as politics, health or the environment, on fringe spaces like 4chan and 8kun or more mainstream places such as Instagram? And how can we track their spread across the web? This recipe will give you the tools to surface misleading memes across a range of subjects and platforms.
This recipe is intended for journalists and researchers who have some coding experience in Python or R. It assumes you have installed Anaconda on your machine (or know how to install it) and are familiar working in Jupyter notebooks.
In the following recipe we will be looking specifically for climate change-related memes that contain misinformation, such as the idea that climate change does not exist, that it is not man-made, or that climate change has stopped and we are now going through a period of cooling.
Ingredients
1. 4CAT. 4CAT is a dashboard-like tool that scrapes data from Reddit, 4chan, 8chan, 8kun, Breitbart, Instagram, Telegram and Tumblr. It hosts a suite of natural language processing and other statistical tools designed to facilitate the study of social media content and misinformation. The tool is free and there are detailed instructions on how you can install 4CAT on your own computer or server.
2. Google Sheets.
3. CrowdTangle. CrowdTangle is a Facebook-owned tool that allows you to monitor and analyze social media content. It is free for journalists and researchers but you will need to sign up if you don’t already have access.
4. Search Endpoint of CrowdTangle’s API. With access to CrowdTangle, you also have access to its API. However, you will need to make a specific request to access the Search Endpoint of CrowdTangle’s API. You can make that request here.
5. Python and Pandas and Anaconda. Anaconda is a data science platform that comes equipped with an assortment of Python packages. It also comes with Jupyter Notebook, a computational notebook used for the interactive development of data science projects. (The examples in this recipe will be coded in Python, but you can also use R.)
5. Selenium. Selenium is an automation tool used to drive web browsers.
7. BeautifulSoup. BeautifulSoup is a Python library used, among other things, to retrieve data from HTML files.
8. Google Cloud Vision API. The API gives you access to pre-trained machine learning models that you can use for facial detection and labeling. We will use it for its reverse image search feature. You will have to sign up to use the Google Cloud Vision API. While it gives you free credit to explore the API’s features, if you are going to be using it frequently or using large amounts of data, you will have to pay to access its features.
9. A text editor such as Sublime or Atom.
10. An Instagram account.
11. RawGraphs: a visualization tool.
Steps
1. For this recipe, we will be looking for misleading climate change-related memes over the past year. To do this, we need to generate a list of keywords. You may have already collected relevant keywords and phrases through your own monitoring. However, if you don’t have a pre-existing list, one way to generate relevant keywords is to create a dataset on 4CAT.
2. Open 4CAT, select 4chan and enter your query. We will use “climate change” for this example and we will use the timeframe April 1, 2020 to April 1, 2021.
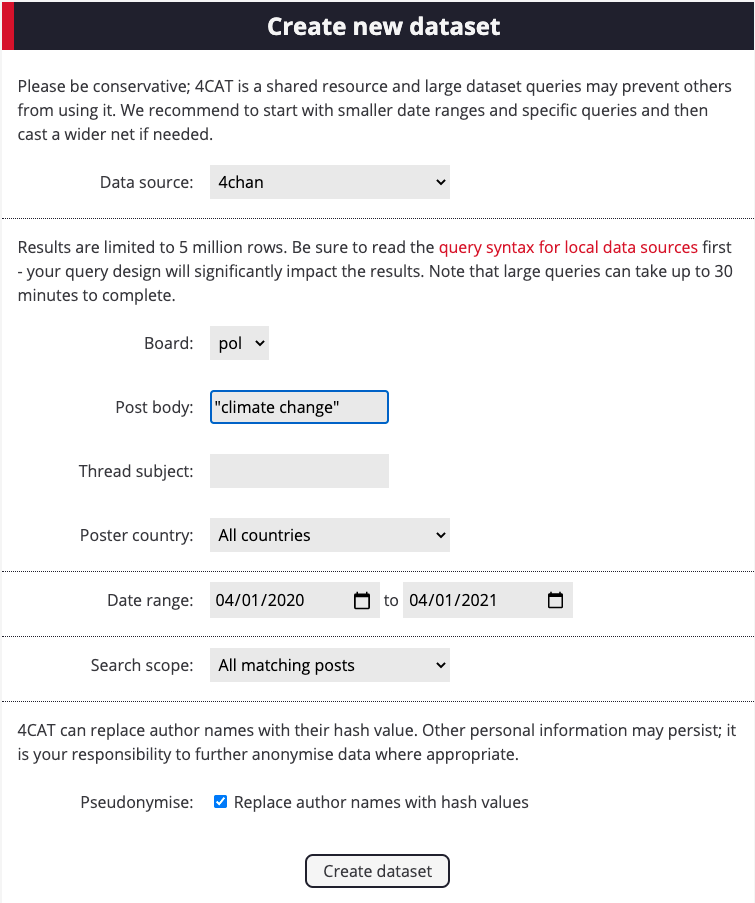
3. Click on Create Dataset and then click on the resulting output file. This will direct you to the analysis page.
4. To gain a sense of problematic terms, you can try zooming into words that are frequently associated with your original query (“climate change”). 4CAT has different ways of finding frequently associated words: with word embeddings, word collocations, word2vec and word trees. Let’s first try word trees. If our dataset contains over 100,000 rows, we may also try word2vec, which finds word associations in large bodies of text.
5. At the very bottom of the page, run the word tree module by indicating the keyword or root query you want to see mapped. For this example, we will use the word change. We chose change because we are interested in capturing problematic keywords and phrases that follow climate change. You can choose to see sentences preceding or following that word, and you can also indicate how long you would like those sentences to be (window size). We have chosen a window size of 15 and a max branches/level of 10.
When done, your SVG result should appear similar to this.
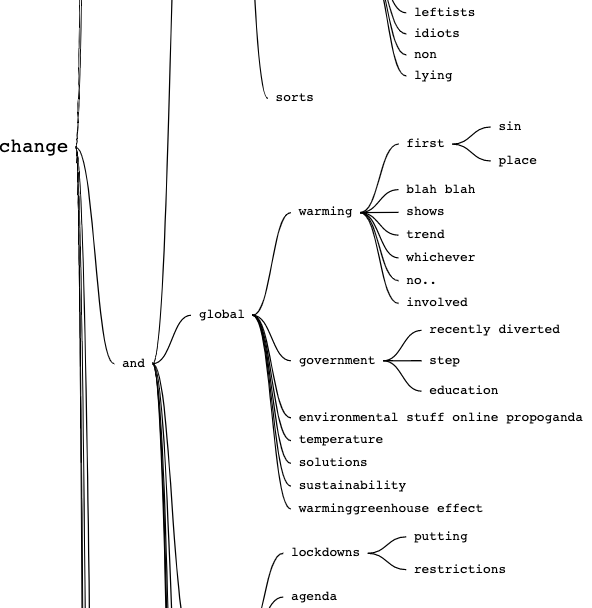
6. Investigate the word tree and identify problematic terms that stand out, such as conspiracy theory-related terms or terms that challenge the science around climate change. We can see in our tree words such as fake (as in the false claim that climate change is fake), depopulation propaganda, agenda, greta, skeptical, population control, naturally (as in climate change is naturally occurring as opposed to human-driven), socialist, marxist and losing freedoms, among others. Having previously investigated climate change conspiracy theories on 4chan in a different recipe, we already have other keywords, such as hoax and scam, that we can add to this list.
7. Now, create a new query in 4CAT using a Boolean query to capture these keywords in the context of climate change. We will use the following Boolean query: climate (fake | depopulation | propaganda | propoganda | agenda | skeptical | population control | control | natural phenomenon | naturally | hoax | scam | freedom | greta).
Remember 4CAT requires a slightly different Boolean syntax which you might not be used to. The pipes ( | ) in the above query signify OR statements.
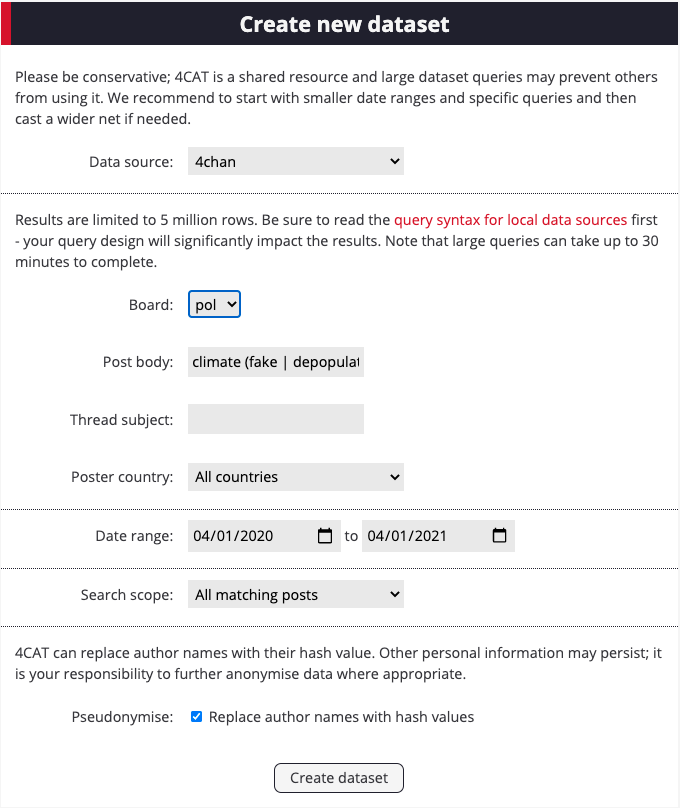
8. Click on the resulting output file. On the analysis page, click on Create image wall, sorting the images by dominant color.
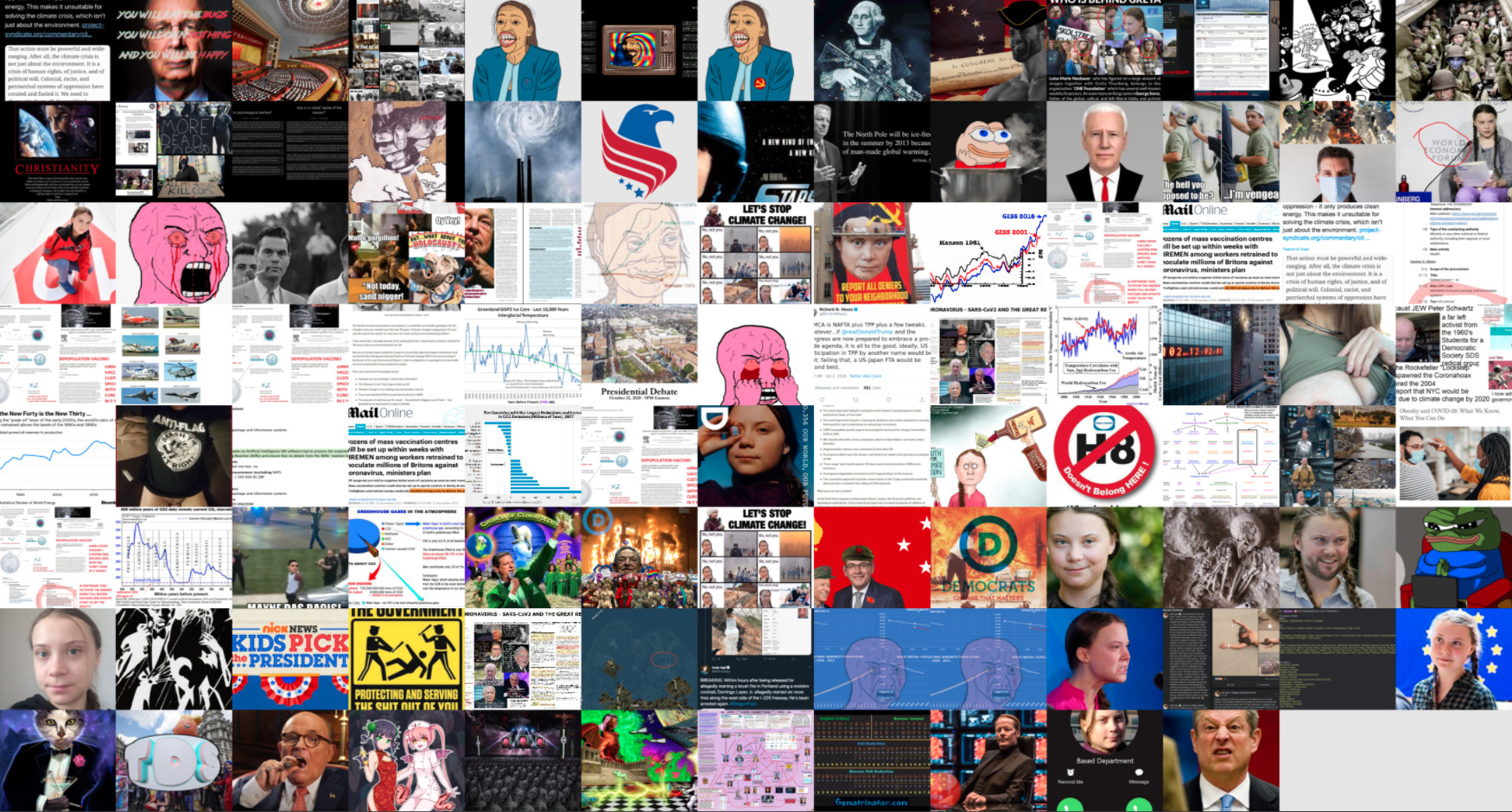
9. Click on the resulting SVG file. The image wall shows the 125 most popular images in the dataset. From a cursory scan, we get a sense of the key figures linked to climate change policy (Greta Thurnberg, Joe Biden, Alexandria Ocasio-Cortez, Al Gore and Klaus Schwab) who are being targeted on 4chan. Interestingly, we also see various data visualizations pushing the idea that the sun is driving climate change — claims that have been roundly debunked.
10. Scroll down to the Post Metrics section in the analysis page and click on Top Images.
11. Click on the resulting “csv file” to download it to your machine.
12. Open the file in Jupyter and use the following code to grab the top 125 most-shared images in the dataset, format the image URLs so they are web-readable, then save the file to your computer.

13. Import the file in Google Sheets. Your spreadsheet should have one column with 125 image URLs.
14. Resize the rows so that the row height is 250 pixels. You can play with the sizing of the rows once you have loaded the images.
15. Click on the second row in column B (right below the column header). We have given the column header the name image. Then navigate to the Functions tab, scroll down to Google and then click on Image.
16. Now click on row A1 and hit return or enter. Grab the little square in the bottom right corner of B1 and either double click on it or drag it to the bottom of your dataset.
17. Column B should now be filled with the images that correspond to the image URL in column A. In this example, we are only interested in memes (images with overlaid text) and data visualizations that push misleading information or conspiracy theories about climate change. Manually inspect all the images in the spreadsheet and remove rows that don’t adhere to this criteria. Then save the file as a csv file.
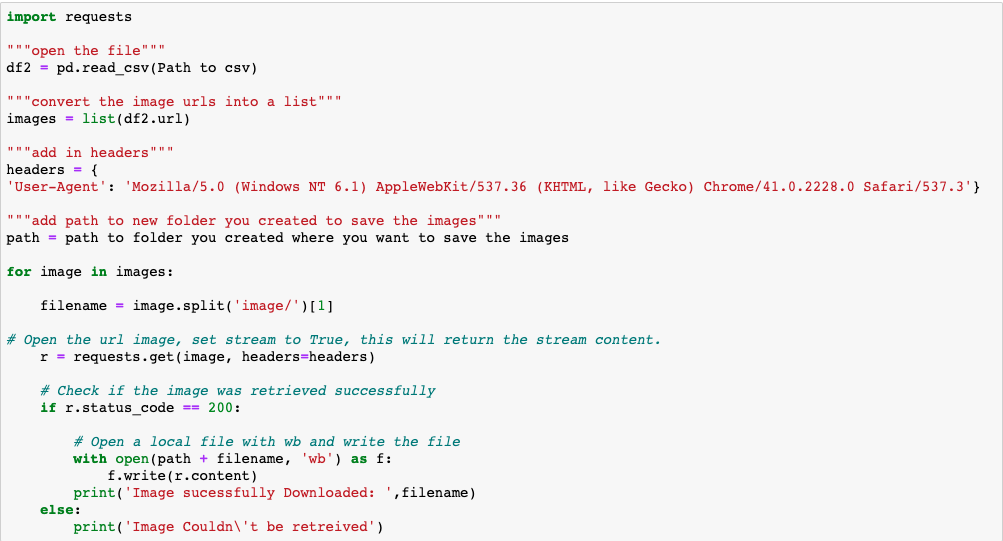
18. Create a new folder on your computer to store the 4chan memes. Open the csv file you just saved in Jupyter and run the code below. The script will convert the image URLs to actual images and save them on your computer.
If you want to investigate memes on 8kun and Reddit, you can repeat steps 1-18, selecting 8kun and Reddit instead of 4chan when creating your datasets. For the next part of this recipe, we are going to collect misleading climate change-related memes from Instagram using CrowdTangle.
19. Navigate to the CrowdTangle dashboard you used to request access to the CrowdTangle API Search endpoint. Retrieve your API token from the settings menu in the dashboard.
20. In the text editor of your choice, use the search endpoint to query the CrowdTangle API and save the output as a csv file. We will use the same Boolean query as before. However, this time it will be formatted for the CrowdTangle API. You can see the parameters we used to query the API below, including how we formed our Boolean search. You can refer to CrowdTangle’s GitHub Wiki page for all its API documentation.
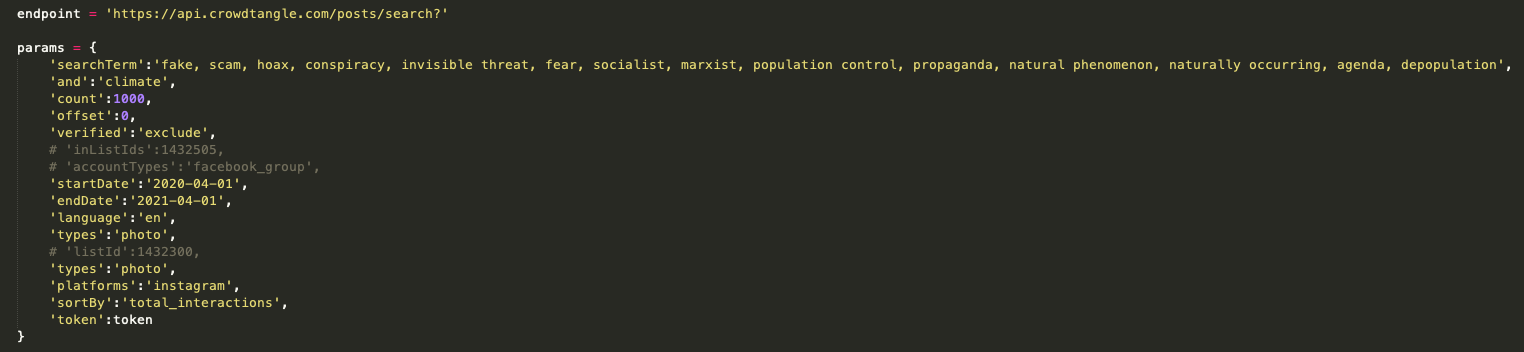
We filtered for only unverified accounts in our parameters. We did this to avoid posts from large news organizations and brands, which generally capture the most engagement but in this case are not relevant to what we are looking for.
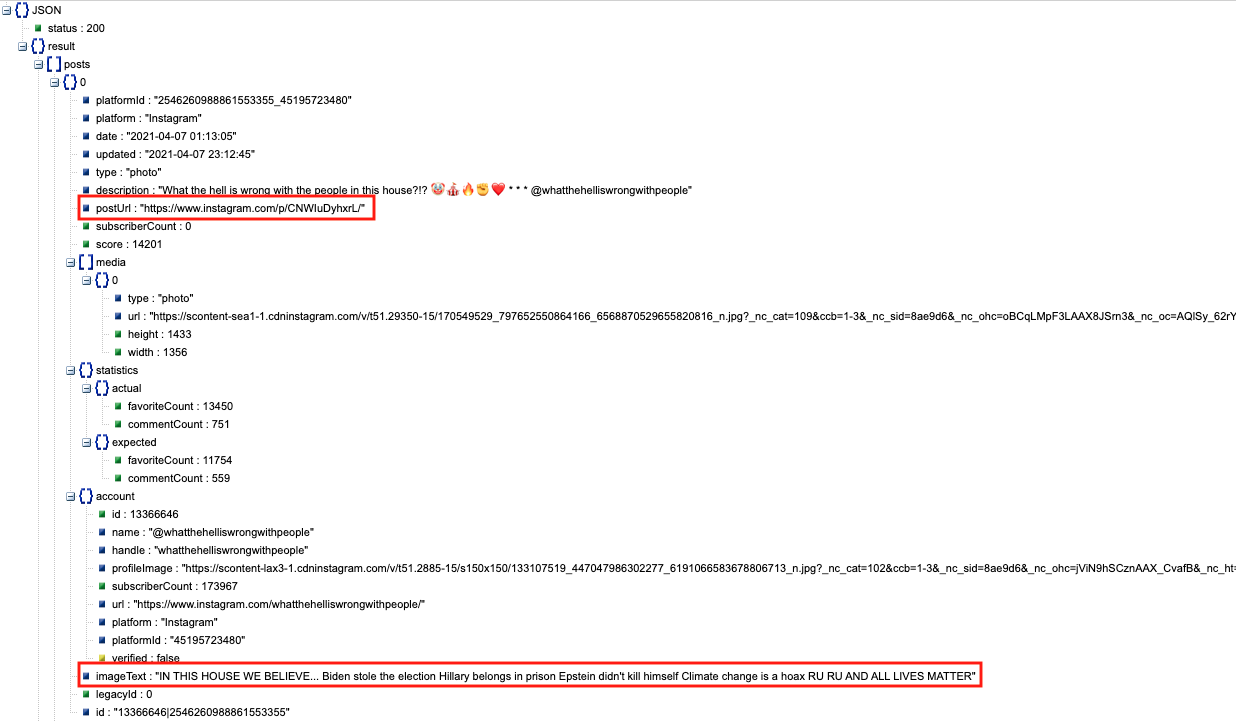
Make sure you grab the fields postUrl, imageText and statistics when you make your API request as they are important for filtering specifically for memes. The postUrl field refers to the URL of the Instagram post. The imageText field shows the text that is overlaid over the image. And statistics provides a count both for the total number of likes (favoriteCount) as well as comments (commentCount). You will want to get the numbers from the actual field as opposed to expected. These reflect the real number of likes and comments compared with those predicted by CrowdTangle. You will probably want to create a separate field in your csv file for total interactions where you aggregate commentCount and favoriteCount.
For other investigations, however, you may want to use a combination of different fields provided through the API. Below you can see all the different JSON fields that accompany each post.
21. Open the resulting csv file in Jupyter. Make sure you have imported the following packages.

Because the search endpoint will look for our Boolean query in multiple fields, including the body of a post, many of our results will be images without text instead of memes. To isolate memes in the data we will have to construct another Boolean query that looks specifically for matches in the imageText field. We will use the code snippet below to filter for relevant memes.

The resulting dataset should now include only posts with memes that match your Boolean search.
22. Data from CrowdTangle’s API supplies the image URL for Instagram posts. Clicking on this URL will open a new browser tab and show you only the image for that particular Instagram post. You can find the image URL under the media field as url. However, these URLs have a short shelf life and expire after a few weeks. If you were looking back over several months’ worth of data, these links would no longer function.

To get around this, we will have to build a script in Python that uses Selenium and BeautifulSoup to open Instagram, iterate over each post, extract the live image URL contained in that post and save the output to a csv file. You will have to have your own Instagram account to perform the following script as it will require you to enter your username and password.
You will need to add the following function to the script. If there are any exceptions when iterating through the Instagram posts and extracting their image URLs, this Python function will be called.

Here is the bulk of the code we will use to extract the image URLs and store them in a new dataset. It’s good practice not to make too many requests to a server in a short period of time as this burdens the system and you could be blocked from the server. As a consequence, various sleep() calls have been added to the code.
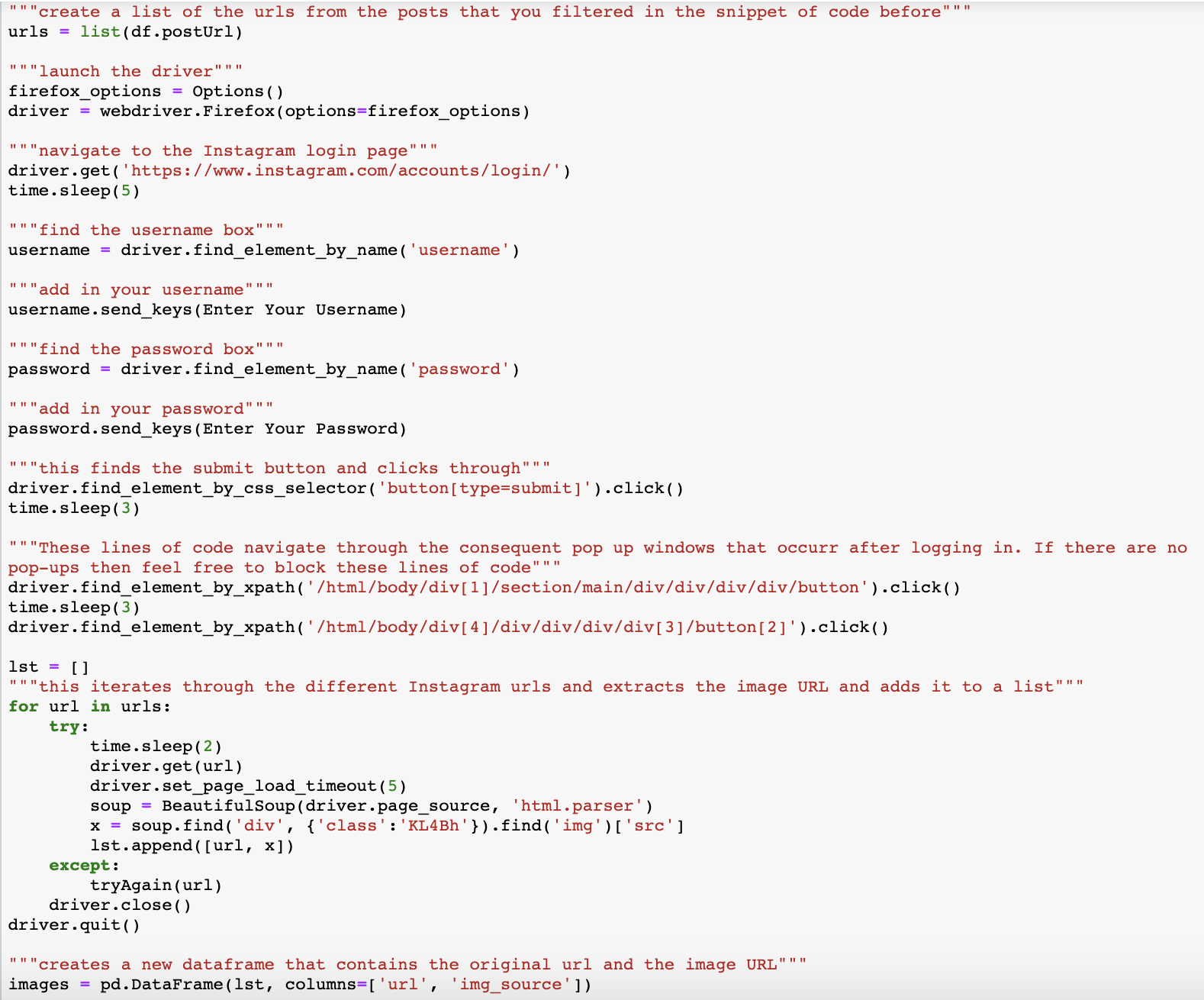
23. Similar to what we did above with our 4chan image URLs, save the most engaged-with 125 posts as a csv file and then import the file into Google sheets.
24. Repeat steps 14-17 of this recipe.
25. Create a new folder on your computer to store the Instagram memes. Open the csv file you just saved in Jupyter and run the code snippet below, converting the image URLs in the column img_url into jpg files that will be stored in the new folder.

From those 250 images on 4chan and Instagram, we selected 30 memes to investigate further. Already we are seeing a few potential story ideas emerge from the collected memes: for one, the link between different conspiracy theory communities, such as those that promote the unfounded Great Reset theory and those that see climate change as a hoax; also, the presence of climate change denialist posts on Instagram, despite parent company Facebook’s announcement that it would take steps to limit the reach of climate misinformation.

26. We now want to see where else these memes may have appeared on the web. To do this we will use the Google Vision API and specifically the Detect Web entities and pages feature, which will reverse image-search each meme and return a list of up to ten URLs where the meme is located. Like all image recognition software, the Google Vision API detection feature may return some false positives, so it’s important to manually check links that you are unsure of.
27. In the following script we will iterate through the images in the two folders where we stored our memes, identify the URLs linked to each meme using the web detection feature (here is the full documentation on how to make requests) and then create a new dataset with those URLS.
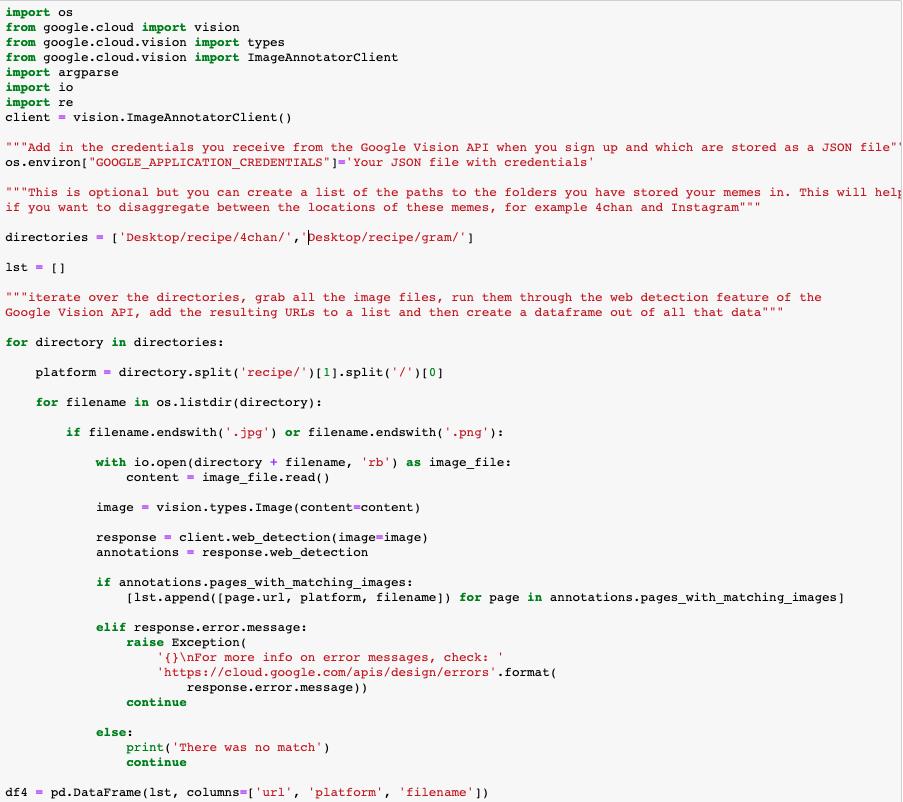
We now have a dataset which contains the URLs connected to each meme, the platform where we surfaced the meme (4chan and Instagram) as well as the name of the meme image file that we stored on our computer. The name of the image file is important, as the web detection feature might not recognize all of the memes you identified and, as a consequence, URLs connected to that meme will not appear in your dataset. Having the image file allows you to identify which memes the web detection feature has successfully identified.
At this point you may want to investigate some of the individual URLs to get a sense of the sites where these memes appear. If you are tracking the origin of a particular meme, you would also want to check the time at which the meme was uploaded on each website, working backward until you find the earliest version. Tracking the spread of a single meme might in itself be fodder for a story or investigation.
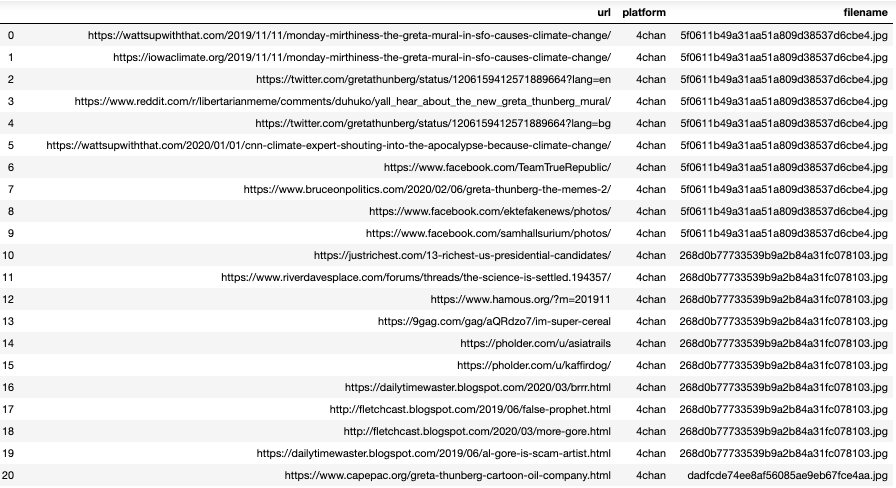
28. To make more meaningful sense of the URLs, we will extract the domains within each URL to see which sites are providing the most space for these memes. We use the tld Python package and the following code to do this.

29. To visualize the data, first save the dataset as a csv file, filtering for only the columns platform and domain. Now upload the csv file in RawGraphs and select Alluvial Diagram. Navigate down to Mapping and drag the two dimensions (platform and domain) to Steps.

The output should look like this.
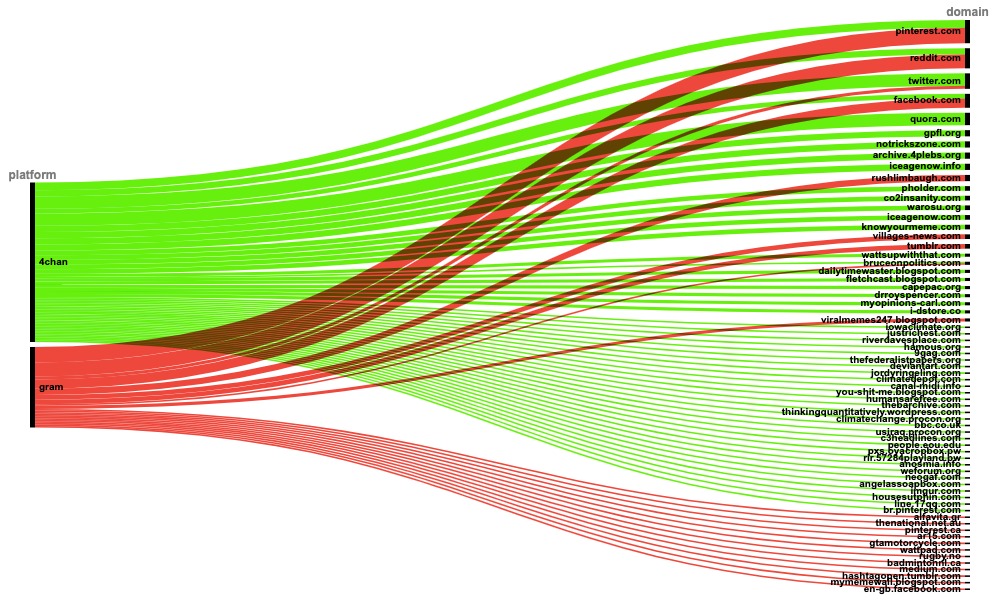
Unsurprisingly, mainstream social media platforms appear most frequently in the dataset. However, Pinterest’s position at the top stands out because its role in the flow of misinformation is often overlooked. The fact that some of the memes we discovered have found a home on Pinterest, despite the platform’s clear guidelines against conspiracy theories and misinformation, could merit further investigation. The appearance of Reddit at the top is also notable, suggesting that the platform is still being used to beta-test memes.
You can also see more fringe platforms and websites such as iceagenow.com and co2insanity.com, among others, where these memes found a home. These sites likely host other similarly problematic content.
Remember, this recipe is not strictly linear. You can mix and match different tools in the recipe depending on what you are working on. For example, you may already have a set of memes that you want to track, and thus only the second part of this recipe would be useful. Or you might want to use the Selenium script to gather all the images connected to a specific hashtag on Instagram. You might also be interested in a different aspect of the Google Vision API, such as entity labeling. The recipe is meant not only to assist journalists and researchers working close to misinformation, but also to inspire people to get creative with their online investigations.
Stay up to date with First Draft’s work by becoming a subscriber and following us on Facebook and Twitter.


