
This recipe is the third in our Digital Investigations Recipe Series, a collaboration between the Public Data Lab, Digital Methods Initiative, Open Intelligence Lab and First Draft. It is designed to lift the lid on advanced social media analysis.
Introduction
Whether you are monitoring misinformation on YouTube around a political wedge issue, tracking the spread of a particular conspiracy, or strengthening your Boolean search queries by better understanding the vernacular of a particular community, the following recipe gives you the tools and methods to supercharge your monitoring and online investigations into problematic YouTube videos shared across a range of fringe platforms.
As a journalist, what if you were interested in investigating misleading or false claims on YouTube around mail-in ballots, for example? How would you go about finding these videos? You could manually search the YouTube platform. But this would likely be tedious, time-consuming and likely result in more media news YouTube channels that may be talking about mail-in ballots, but are not necessarily spreading falsehoods.
A more streamlined approach would be to turn to 4chan, Reddit or 8kun — online spaces known for their divisive and problematic content — and scrape YouTube URLs from posts related to mail-in ballots. The following recipe details how you can do this without having to be an experienced coder. All you need is a basic knowledge of how to use a spreadsheet.
Ingredients
1. 4CAT. 4CAT is a dashboard-like tool that scrapes data from Reddit, 4chan, 8chan, 8kun, Breitbart, Instagram, Telegram and Tumblr. It hosts a suite of natural language processing and other statistical tools designed to facilitate the study of social media content and misinformation. The tool is free and there are detailed instructions on how you can install 4CAT on your own computer or server.
2. A spreadsheet editor (e.g., Numbers, Excel, LibreOffice Calc or Google Sheets).
Steps
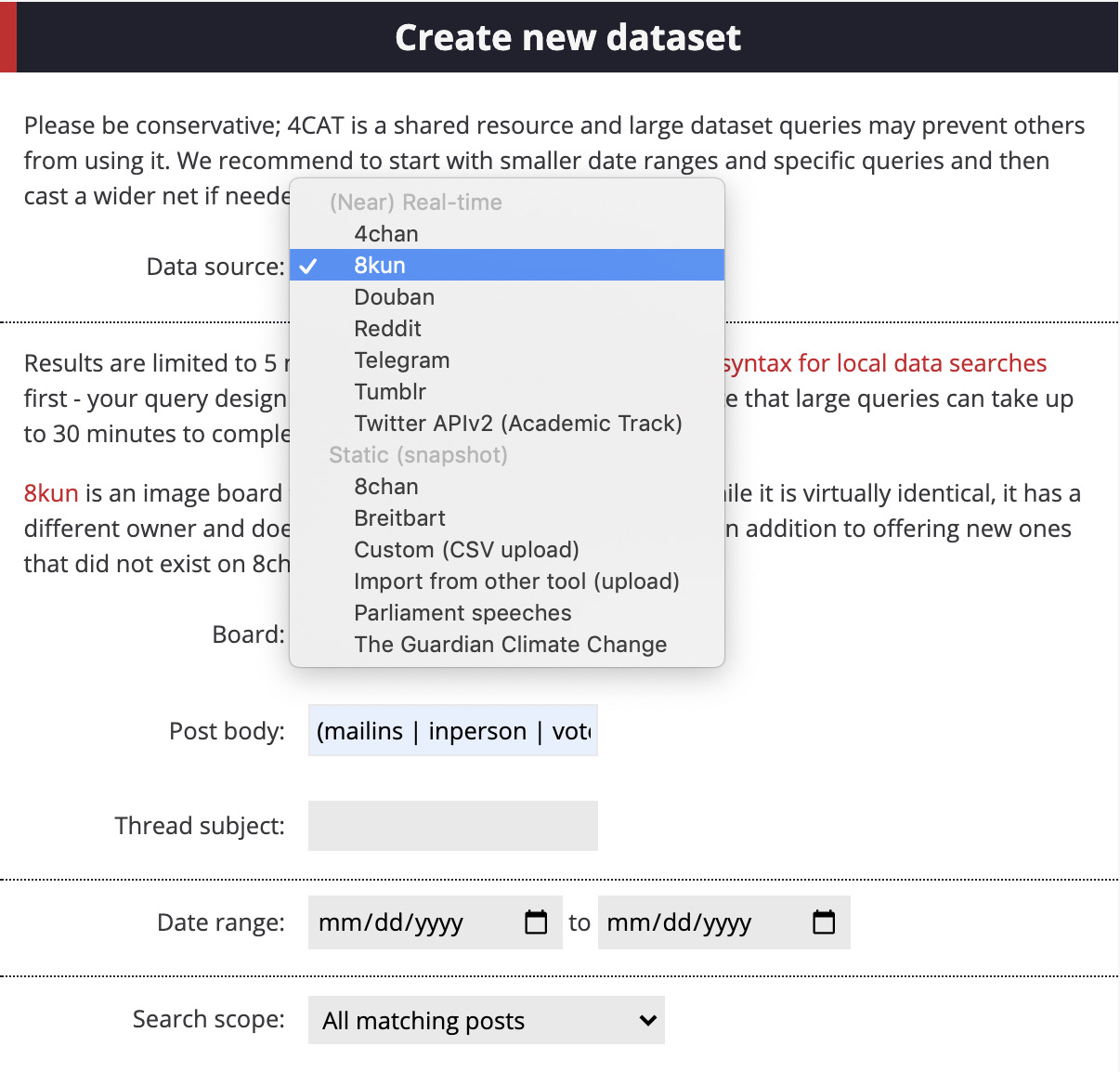
1. On 4CAT, choose 4chan, 8chan, 8kun, Reddit or any other source of YouTube URLs you want as datasets. Remember: the intention is to map the “YouTube diet” of communities spreading conspiracy theories and other misinformation, so you first need to determine the issue you want to investigate; for example, anti-vaccination narratives or rumors.
2. Choose a board or subreddit within your chosen platform. For this recipe, we have chosen 4chan’s “politically incorrect” board, indicated on 4CAT by the abbreviation “/pol”.
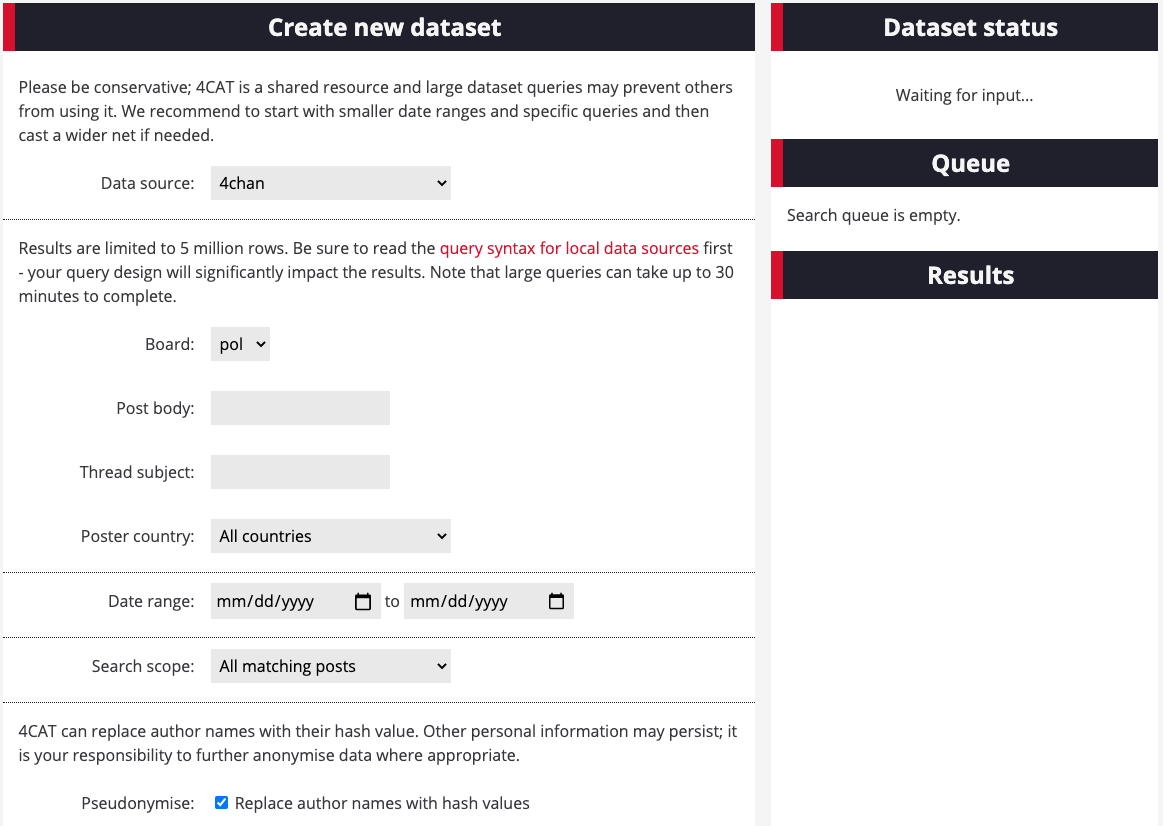
Now choose an issue you would like to query. For this example, we are interested in exploring the issue of mail-in ballots. To capture a wider phrasing of the issue, try: “mail in” | “vote by mail” | “voting by mail” | “ballot fraud” | “ballot harvesting” | “voter fraud” | “voting fraud” | “vote fraud” in the post body search. Some advanced search terms and Boolean queries on 4CAT may be different from what you are used to. For example, 4CAT uses pipes ( | ) instead of the Boolean statement OR. You can find more information on how to form Boolean queries on 4CAT.
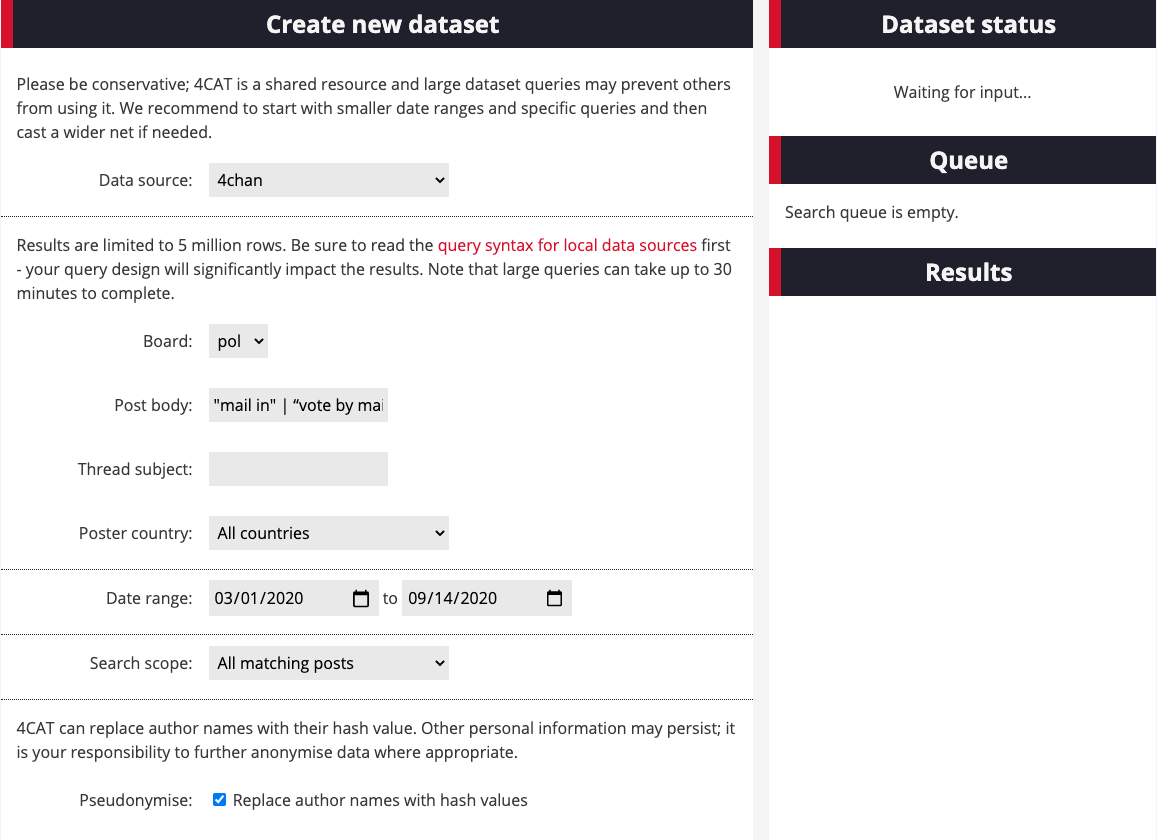
? Remember to discard terms such as “mail,” “voting,” “vote” or “ballot,” which are quite general and may result in many false positives. Instead, think of terms used by people or communities with a particular agenda or a strong opinion about an issue. For example, the terms “ballot fraud,” “voter fraud” and “ballot harvesting” are generally used by people who oppose voting by mail. See here on how to form Boolean queries/advanced searches using 4CAT.
3. Choose a date range appropriate to your issue. For this example, we will focus on posts since March 2020, when Covid-19 started affecting the US, and allegations of fraud resulting from mail-in ballots began to be a highly politicized issue.
?When querying 4chan, thread subject will always refer to “generals,” which is 4chan lingo for recurring threads about a given topic.
5. When it finishes, click on the Results. 4. Now, click on Create dataset. It will take approximately 1-2 minutes to run, depending on your queries. 4CAT will notify you when your dataset is ready.
6. Scroll down to a module that says YouTube URL metadata, then click on Run. You can choose the amount of results you want by adjusting the parameters option. If you select “0” it will get all the YouTube videos in the dataset.
7. Open your results as a CSV (spreadsheet format). We will be using Google Sheets for this recipe.
8. Clean up your spreadsheet for visual convenience. Select the first row, format it in bold, and then, under View, query “freeze” and select Freeze 1 row.
9. You will see that your spreadsheet is ordered by those referenced_urls (YouTube videos) that have appeared the most in your 4chan dataset. That is, those at the top have been referenced the most by 4chan users (indicated by their YouTube video ids in the column id).
10. For your analysis, consider looking at other engagement numbers. The number of views, comments, likes and dislikes a video has is indicative of how much public relevance it holds. Have a look at the columns: video_view_count, video_comment_count, video_likes_count, and video_dislikes_count. Remember: These numbers do not represent views, comments, likes or dislikes accumulated on 4chan, but on YouTube.
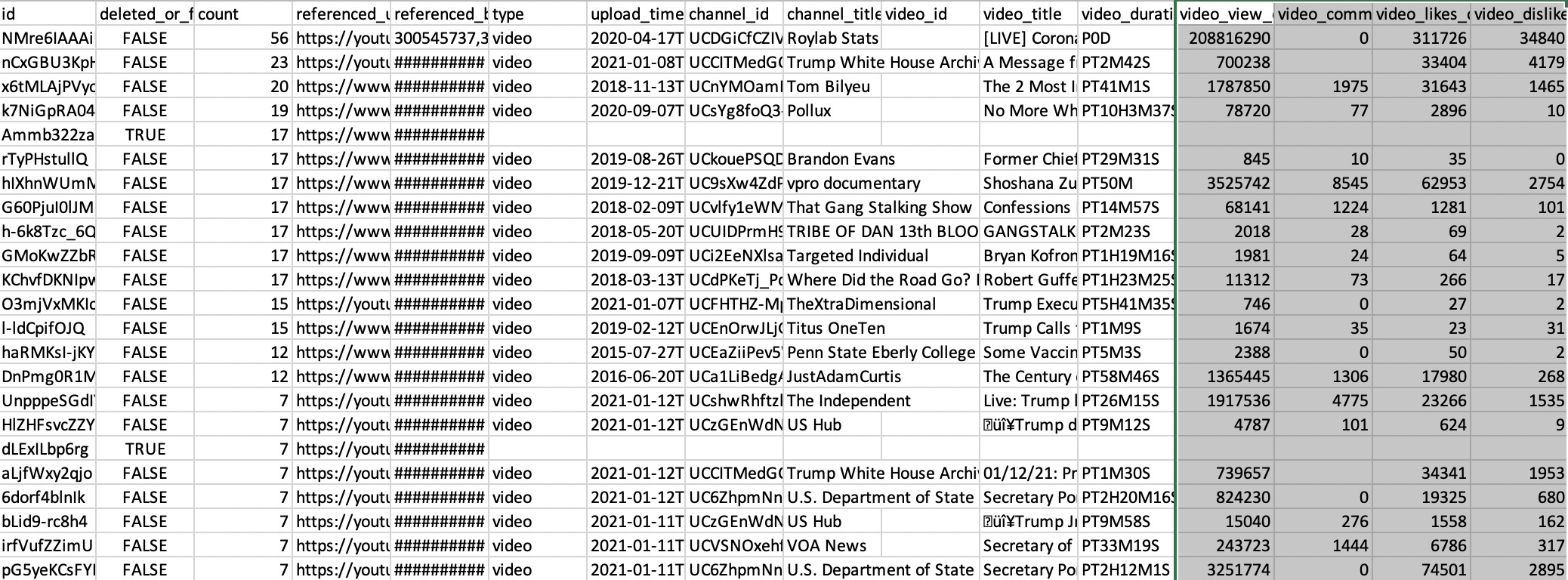
? Because misinformation thrives on emotive content, consider paying particular attention to the column video_comment_count, out of 4chan, often sources of misinformation themselves.
11. Be careful of false positives. While the 4CAT search function is very robust and will dig up posts that match your Boolean query, the YouTube URL metadata tool indiscriminately pulls YouTube URLs from these posts. Often these YouTube links are unrelated to your initial search query; indeed, they are often random music videos or memes. One way of winnowing out false positives is to search in the column video_title for relevant keywords. To do this, create a new column and use =LOWER(K2) to copy the values from the column video_title and convert them to lowercase (K2 refers to the first row in the video_title column). Then create another new column and add in =regexmatch(L2, “mail|vote|steal|fraud|ballot|post|harvest”). Similar to the Boolean search in Step 3, the pipes ( | ) work as OR statements. This equation will look for any of these words in the new lowercase video_title column. If there is a match, it will label the row TRUE. Filter your dataset to get only TRUE values in this column, or delete the rows that don’t contain that value.
12. You may also want to explore which videos appeared most frequently in the dataset. You can find this data in the count column, which should come ranked from highest to lowest already. In this case, count refers to the number of times the video appeared in the dataset you scraped from 4chan. Videos with a high count number can be a good gauge of polluted or misleading content.
? The video Don’t let the Democrats steal the 2020 Election with Universal Vote by Mail has the highest percentage of comments per likes of the videos in the dataset, which is unsurprising after watching the video. The YouTube video uses polarizing language and is full of misleading claims. You may want to plug this url into the Google Search Engine Scraper to see where else it is appearing. See the recipe Tracing YouTube videos across the web for more information on how to do this.
13. Go back to the Analysis page on 4CAT. In the Presets section, run Extract neologisms. This algorithm finds words that may not be immediately visible outside of 4chan, but are used by particular “in-groups.” Knowing this vernacular is important to ensuring that your future searches and data scraping reveal content that is specific to your beat or the community you may be investigating and eliminates many of the false positives resulting from more general searches. You can use relevant neologisms in new searches to build on your pre-existing dataset or you can add them to ongoing keyword lists you may use for monitoring.
14. Open your results. Consider choosing the most frequently mentioned words from your list of neologisms, words that obfuscate items easily flagged by automated misinformation and/or hate speech detection (e.g., “5G” could be phrased as “5gee”) or alternative spellings of keywords used by in-groups.
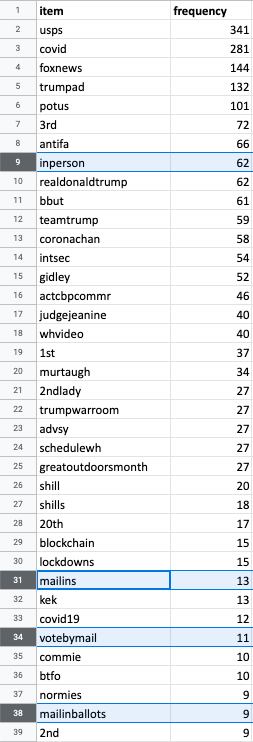
15. Go back to the Create dataset page in 4CAT and use your chosen neologisms as queries. In this case, we will use a few alternative spellings of keywords from our previous search (mailins, inperson, votebymail, mailinballots) to bulk up our list of videos.
16. Obtain YouTube URL metadata with your new obtained results and merge this dataset to your pre-existing one. You can do this by opening the new CSV and copying and pasting the new data under your original dataset.
17. If you are interested in investigating other platforms offered by 4CAT, such as 8kun, Reddit and Telegram, go to the Create new dataset page of 4CAT, select one of those platforms and then repeat the aforementioned steps. Add the new data to your original spreadsheet and remove any duplicates.
? Remember: 8chan was discontinued after August 2019, so data does not go beyond that point. If you choose 8kun and Reddit instead, consider a board and subreddits that are relevant to your investigation. 8kun’s pnd is its board for politics. For Reddit, you may want to focus on subreddits where discussions of voter fraud take place, such as r/freeworldnews, r/conservatives, r/Conservative.
You also now have a set of new keywords (neologisms) specific to your community or issue of interest. If you are looking at the entire history of an issue, you can use the date and engagement metrics to show how issues have risen or fallen in popularity over time and what videos may have driven that debate on YouTube.
 You now have a robust set of YouTube URLs related to your beat, many of which may be misleading, extremist or just plain false. You can use this list to underpin investigations into problematic content hosted on YouTube itself; for example, to test whether the platform is proactively policing dangerous misinformation or other content that violates its community guidelines. Or you may use these videos as evidence for how certain communities or political parties are using YouTube to amplify their narratives or ideologies.
You now have a robust set of YouTube URLs related to your beat, many of which may be misleading, extremist or just plain false. You can use this list to underpin investigations into problematic content hosted on YouTube itself; for example, to test whether the platform is proactively policing dangerous misinformation or other content that violates its community guidelines. Or you may use these videos as evidence for how certain communities or political parties are using YouTube to amplify their narratives or ideologies.
And using the recipe Misinformation networks on YouTube: recommended videos, you can investigate the videos YouTube recommends based off of the set of YouTube URLs you just compiled.
Emillie de Keulenaar is a PhD researcher at University of Amsterdam’s Open Intelligence Lab and Simon Fraser University’s Digital Democracies group. She has previously researched with the UN’s Innovation Cell, the Dutch digital humanities cluster CLARIAH, the European Time Machine consortium and the Clingendael Institute. Her interests lie in the role of deep disagreements in producing misinformation, as well as in the history of moderating online hate speech and other problematic information.


