Imagine you are researching an anonymous website with no clues as to its authorship. A single string of code could link that site to another, which perhaps reveals the identity of the owner. With the right tools, this information can be surprisingly easy to uncover.
Site fingerprinting with embedded code
Google Analytics is a popular service that allows webmasters to gather user statistics – such as country, browser and operating system – across multiple domains. The string of code added to each page contains a unique user account number — and through this, multiple sites can be linked together. Google AdSense, Amazon and AddThis work on the same principle.
There are several resources available to reverse-search these IDs and tie them to matching sites. My current favourites are SameID (which searches not only for Analytics and AdSense, but also Amazon, Clickbank and Addthis) and SpyOnWeb. SpyOnWeb’s basic service is completely free, whilst SameID allows five free search queries per day.
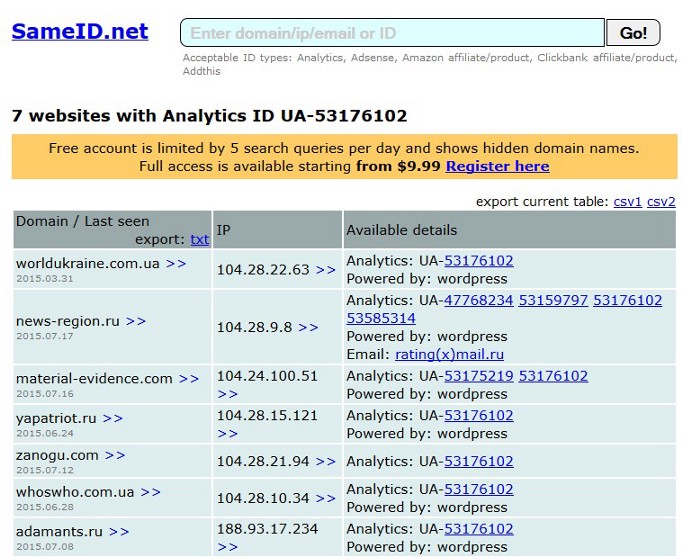
SameID showing Analytics search results
There is also the more advanced NerdyData which searches for matching occurrences of any code snippet you enter. Usefully, the paid subscription version allows results to be saved. However, it sometimes returns multiple analytics matches from the same site which makes searching time-consuming.
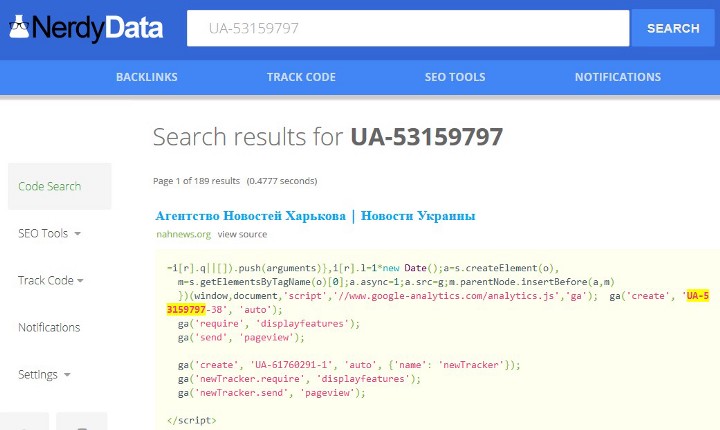
NerdyData will search the web for any code string you enter
MeanPath is a similarly comprehensive code tracking tool, with a free version delivering up to 100 results.
It’s a good idea to cross-check your findings with more than one service, as the number of matches they retrieve can vary. In my tests, SpyOnWeb didn’t find as many sites as SameID, while Meanpath brought up two hits the others missed.
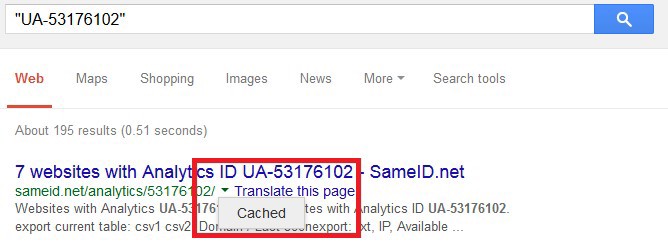
It’s worth searching Analytics or AdSense IDs on Google, too, making sure to use double-quotes (for example, “UA-12345678”). This can turn up further matches from reverse-search tools you haven’t used before.
Additionally, if a website has recently removed or changed its Analytics code, cached Google results from services like SameID may still record the association. Get to the cached version by clicking on the green downward arrow next to the search result:
Verifying with the source code
It’s important to check the information given by any code search tool, and this is easily done by viewing the source of each website’s homepage.
In Firefox, Chrome, Internet Explorer or Opera, right click anywhere on the page and select View Source or simply Source.
In Safari, go to the Page menu on the top right of the browser window and choose the same option:
You will be presented with a window full of code, which you’ll need to search for the ID. Do this with Edit > Find or the Windows shortcut CTRL-F (Command ⌘ + F on Mac). In the search field, enter one of the following tags:
- AdSense: Pub- or ca-pub
- Analytics: UA-
- Amazon: &tag=
- AddThis: #pubid / pubid
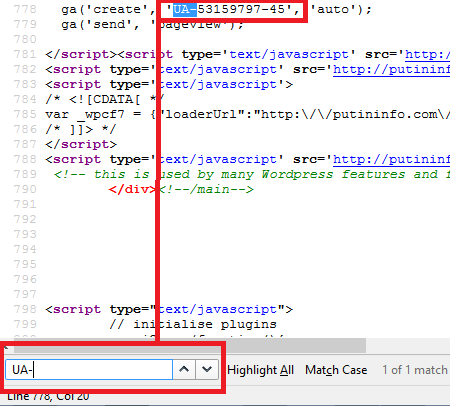
Finding a Google Analytics ID in a web page’s source code
Looking for connections in WHOIS records
Domain registration records can hold valuable information on entities associated with a website. These can include names, e-mails, postal addresses or phone numbers. Although accuracy of these details can vary, here this is less important — we are simply using it to look for associations between websites.
There are many WHOIS services, and it’s advisable to use more than one to corroborate your findings. One of my favourites is Who.Is, which shows historical, as well as current, registration information. This can be useful with a website that has recently switched to an anonymous registration service.
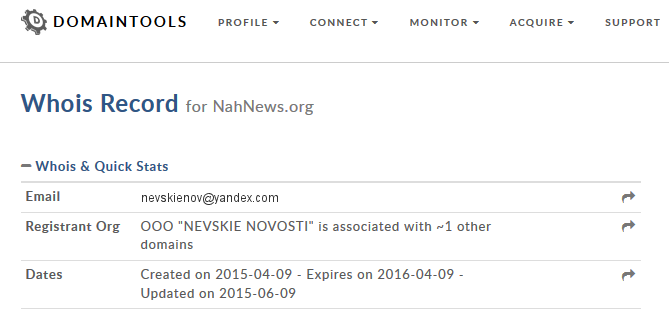
Domaintools showing registrant e-mail and organisation, which may provide links to other sites
Another is whois.domaintools.com, which also displays the type and version of server software used on the site and the approximate number of images it’s hosting. Whoisology not only shows archived results, it will also link e-mail addresses to domains.
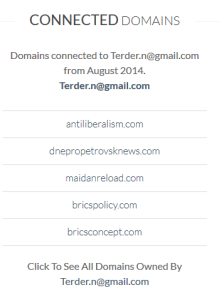
Whoisology showing some of the websites connected to an e-mail address
Some WHOIS services don’t recognise Cyrillic URLs. In this case, try running the address through the Verisign IDN Conversion Tool.
Digging into metadata
Many images and documents you find online contain metadata — information added when the file was created or edited. Bellingcat author Melissa Hanham has already covered the use of metadata to support geolocation. Here, we will look at its potential to link websites.
Social media services such as Facebook and Twitter tend to strip out metadata automatically, but this isn’t always so for the rest of the web. Smaller websites and blogs often leave it in.
Two of the best tools I’ve found for viewing metadata are FotoForensics (which only handles photographs) and Jeffrey’s EXIF Viewer< (which also analyses documents, including PDF, Word and OpenOffice.)

Jeffrey’s EXIF Viewer showing metadata from an ODF document.
There are many types of metadata, but some of the most interesting for our purposes are EXIF, Maker Notes, ICC Profile, Photoshop and XMP.
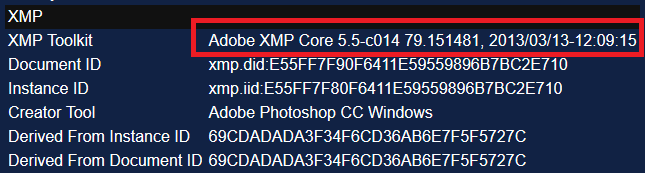
A FotoForensics metadata analysis
These can contain information such as the exact version of the image editing suite used. For example, the XMP field ‘Creator Tool’ may show “Microsoft Windows Live Photo Gallery 15.4.3555.308”.
‘XMP Toolkit’ often gives similar data, e.g “Adobe XMP Core 5.3-c011 66.145661, 2012/02/06–14:56:27”. The key is to focus on fields containing specific, detailed information. If you’re analysing a photograph, the camera’s model number may be present (for example “KODAK DX4330 DIGITAL CAMERA”).
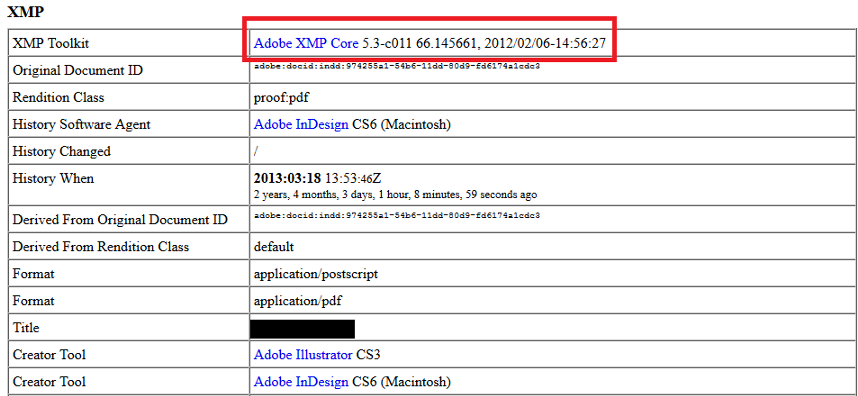
It’s important to note that millions of people may own the same camera model or Photoshop version, so this data can only be used in support of more concrete connections, such as Google Analytics codes. However, document metadata may contain more identifying details, such as the creator’s username.

Occasionally, photographs will even carry the unique serial number of the camera used. This can then be reverse-searched with tools such as Stolen Camera Finder and Camera Trace to find other photographs taken with the same device.
Preserving web pages
Web content can quickly disappear or change, taking the all-important Analytics IDs with it. Fortunately, there are several ways to preserve pages for posterity. It’s good practice to do this not only for sites you’re researching, but also for results pages from tools such as SameID.
The Internet Archive Wayback Machine makes preservation of web pages quick and simple. Once archived, the page’s content cannot be changed, so the resulting ‘snapshot’ is difficult to dispute.
The Wayback Machine also adds a date and time stamp to the archived page’s code for future reference. Features like this have given the tool credibility amongst forensic analysts.

WebCite is similar to the Wayback Machine, though it does allow some site data to be altered by the user. Also, to view the source code of archived pages, you will need to use View Frame Source (under ‘This Frame’ in Firefox) instead of View Source. On the plus side, it sends addresses for archived content straight to your inbox. There is also Archive.is, which can be useful for saving public social media profiles.
There are some caveats with these tools: they cannot manually archive entire sites, only individual pages. Plus, most won’t work if the site is set to exclude crawlers or content scrapers. In this case, the best option is to save individual pages to your computer and/or take screenshots. I use the free tool Web Page Saver by Magnet Forensics, though Windows Snipping Tool and DropBox are also useful for ad-hoc screen capturing.
As a final step in preservation, it’s worth manually submitting the website to Google’s index. This will increase the likelihood of pages being held in Google’s cache for later retrieval.
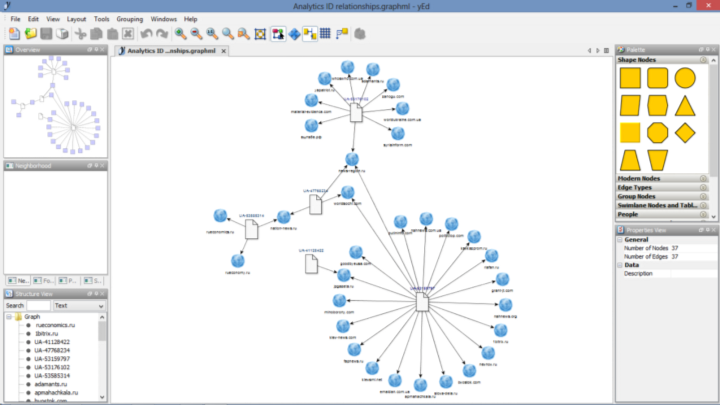
Mapping the network
Investigating large groups of websites can throw up a complex tangle of connections. Visualising these in an entity-relationship graph lets you see them all at a glance.
The free application yEd Graph Editor (for Windows, OS X and Linux) is a convenient tool for building and arranging diagrams, both simple and complex. You can create graphs simply by clicking and dragging icons and drawing links between them.