
The European parliamentary elections are one of the world’s most complicated cross-border polls. Voting takes place over four days in 28 countries, using at least 24 languages.
That presents a challenge for newsrooms, fact-checkers and researchers trying to keep track of how the elections are being discussed online, or looking to spot false or misleading claims.
In the weeks surrounding the election, First Draft supported European media organisations through CrossCheck Europe, a cross-border collaboration to detect and investigate disputed information and how it travels between different European countries and languages.
The first step was to look for words and terms that might be connected to mis- and disinformation during the European parliamentary election.
In order to monitor social media and websites across Europe, we recruited 18 journalism students, speaking over 10 languages, from the London School of Economics (LSE), City University of London and Goldsmiths. The student researchers received training from First Draft on monitoring and verification, before joining us in the office for paid shifts during the fortnight around the election.
Here are the main steps we took to set up social media monitoring for the European elections, which may be useful for other multilingual newsgathering projects.
- Identify topics: Collect keywords and hashtags
The first step was to look for words and terms that might be connected to mis- and disinformation during the European parliamentary election. We began by identifying the most salient and most divisive topics for voters in each country and language.
We identified some main categories of topics, such as gender and identity, anti-Semitism and media bias, and tried to come up with as many keywords as possible for each category. We focused on terms that people actually use on social media, like community-based slang and jargon, as well as polarising terms, rather than how journalists might write in a headline. So, for example, we included “MSM” (mainstream media) as well as “far-left.” We soon reached 300 keywords on 13 topics, in English alone.
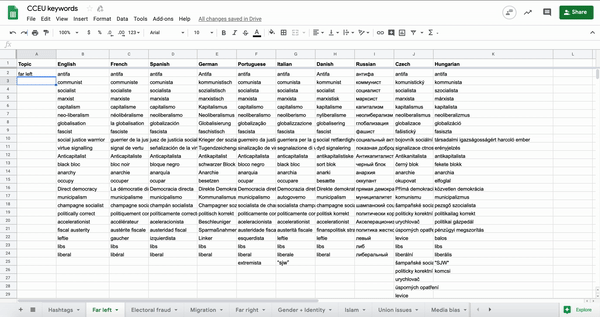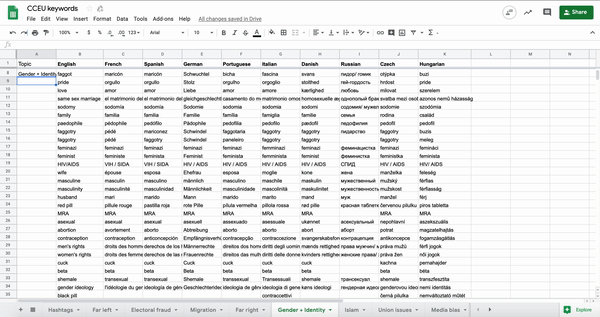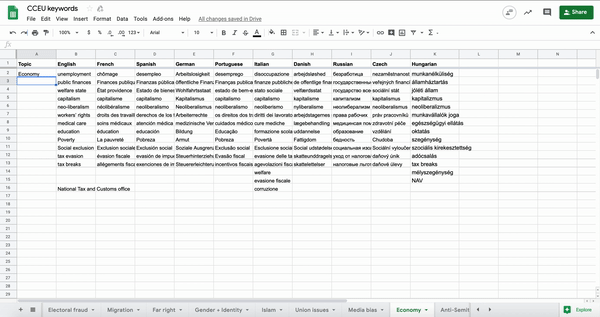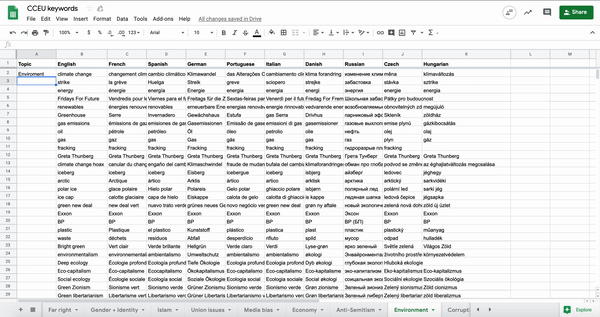
We then translated the keywords into different languages and national contexts. For speed, we first used an automatic translation tool and then student researchers reviewed the keywords in their own languages to make them more accurate – words and concepts were often slightly different in different countries and languages – and add any keywords that were missing. A native language speaker is essential to get these keywords right!
To identify which hashtags to monitor, we first collected well-known hashtags connected to the elections, and then added more hashtags as we found them while we built up our lists of sources.
- Build queries: Create search strings
Next, we converted the keywords into search strings for social media platforms. This would help us scan the platforms for more topics, and start building a list of possible sources of disputed information.
Using Boolean search operators, we created different combinations of keywords for each language. We used ‘OR’ to combine sequences of words and phrases on the same concept. We used ‘AND’ to merge different sequences together, for example, connecting environmental keywords to keywords or hashtags focused on European elections.

A quick way of doing this is to use the function ‘Concatenate’ in Excel to automatically add the ‘OR’ operator to multiple cells. These search strings were compiled in documents for each language, so that they could be quickly referenced by any of the student researchers.
For tweets, we entered the search strings into Tweetdeck, and used filters to look at different types of results. For example, sometimes we wanted to look specifically at unverified accounts, tweets with media contents and links (for example, memes), or just posts with high engagement. We continued to tweak and update the search strings and filters, adding or removing words or phrases until we found something interesting.
- Identify sources: Build lists of accounts
At this point, we were ready to use the search strings to detect accounts, pages and groups that might produce and/or spread disputed information during the European elections.
In particular, we were looking for accounts that were sharing misleading information related to the keywords we had identified or using sensationalist, emotional language. (We were less interested in strong opinions themselves than in understanding how emotions like anger or fear can override critical thinking on social media.) These were not necessarily bots or trolls, but political groups, activists, news websites or individual accounts.
The free CrowdTangle LinkChecker tool allowed us to see which accounts and communities were sharing disputed or suspicious links.
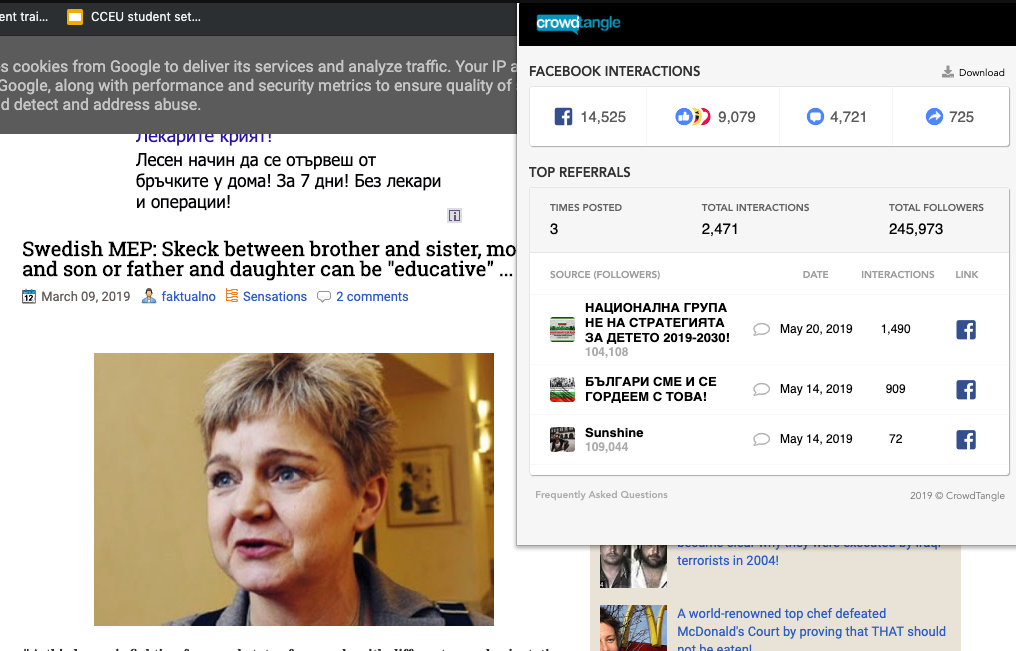
Once we identified a potentially interesting source, we collected the link in a spreadsheet for each country, including Facebook pages and groups, Twitter accounts, Instagram profiles, subreddits, YouTube Channels and websites.
- Monitor engagement and find more sources: Check posts with Crowdtangle
The lists of sources helped us monitor large numbers of potentially interesting accounts. We followed the lists of Facebook groups and pages, Instagram and Twitter accounts, and subreddits in CrowdTangle dashboards, and set up Slack notifications for high-engagement posts.
In Crowdtangle, we searched the top performing posts from accounts in our lists of sources. We could then refine the search to a certain time period and/or a particular type of content. We also used Spike to monitor particular websites and high-performing webpages.
“The lists of sources helped us monitor large numbers of potentially interesting accounts.”
Once we’d found an high-performing page, the CrowdTangle plugin enabled us to find out where it was receiving the most engagement and on which platforms, as well as which accounts were sharing them in which countries and languages.
This helped us understand how much traction a page was getting, as well as identify other potentially interesting sources that were sharing the page.
Days before the EU election, for example, a Russian-speaking student researcher spotted a Bulgarian website and Facebook page that was sharing a misleading story about a Swedish politician, claiming that she was promoting the legalisation of incest. We used to CrowdTangle LinkChecker to discover that the story had received almost 15,000 interactions on Facebook and to identify who was sharing it.
- Basic verification: Use advanced search techniques
Once we identified disputed information in a post or article that was receiving significant engagement, we would ask some basic verification questions. Was the piece of content original? When and where had it appeared before?
Our aim was to better establish the likelihood that it was misleading and whether it was likely to be spreading to other countries. These advanced search techniques included reverse image search, searching by language, site and time period, and looking for connection between sites.
For example, we investigated a German anti-migrant website that was publishing misleading claims about violence by migrants in Europe. By searching the Bitcoin and IP address of the website, we found another associated website sharing a very similar type of content.
Each of the steps we took generated more keywords and potential sources, creating a self-reinforcing cycle that helped us build up larger data sets for monitoring.
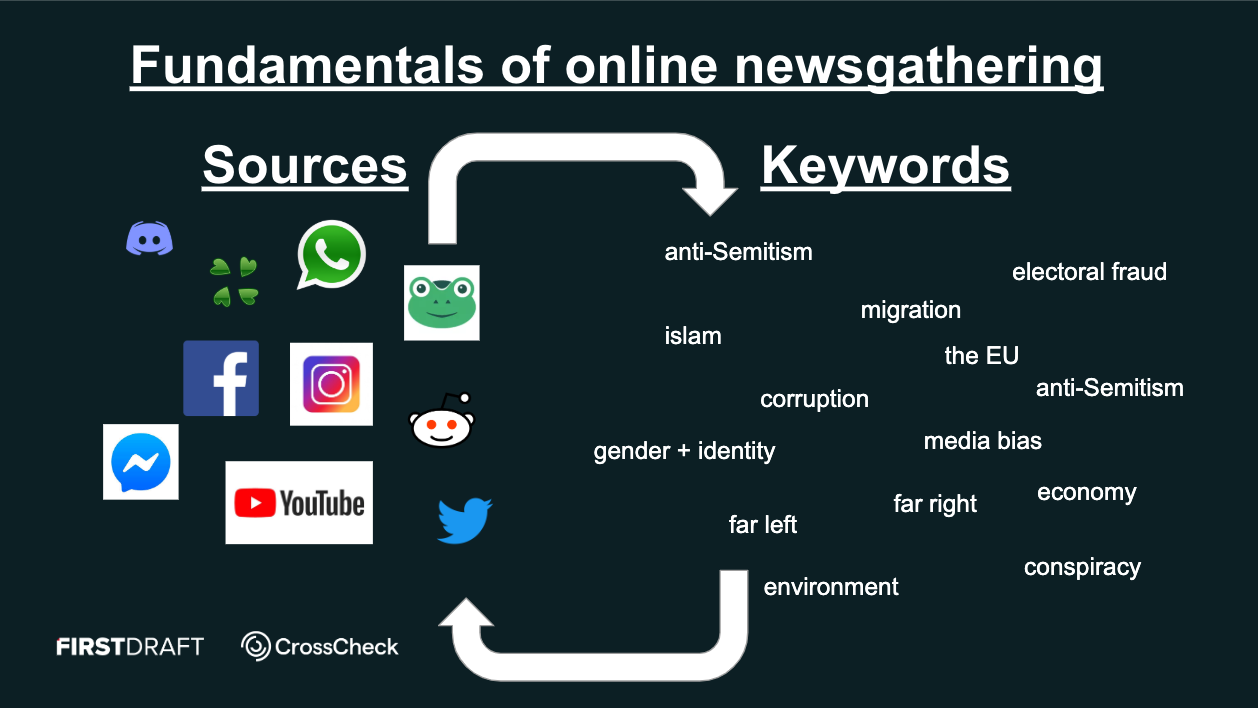
Some of the more challenging questions we faced during monitoring were identifying which misleading content had the potential to cross national borders. How do we trace mis- and disinformation that is being shared in different languages and platforms? What are the best tools to use for different languages? Is there any way to predict the international virality of a local story?
Reverse image search and searching for video frames was one starting point. Translating the key terms in a post into different languages was another. We also followed specific accounts that we had noticed regularly share misleading information which was then picked up in other languages. This was far from comprehensive, but we learned a lot about where to start.
This was just the beginning. But with the volume of information flowing through different languages and platforms, it is more crucial than ever to monitor multilingual social media posts and websites to see how claims, tactics and sources travel across borders.
To stay informed, become a First Draft subscriber and follow us on Facebook and Twitter.
CORRECTION: This story has been updated to reflect that the number of official languages of the European parliament is 24, not 27.


