
Journalists spend much of their time on Twitter and Tweetdeck, looking for relevant news stories, monitoring mis- and disinformation or just gauging trending topics.
But Twitter’s interface and Tweetdeck provide only a shallow look at what is actually occurring on the platform. To better understand what is happening under the surface, such as whether a trending hashtag is being driven by inauthentic means, you need to tap into one of Twitter’s various application programming interfaces (APIs).
The many data fields provided through Twitter’s different APIs let journalists conduct much more meaningful analyses of Twitter activity and find interesting stories, such as identifying the criss-crossing of political rhetoric between countries or spotting how political activists from one country support presidential candidates in another.
With the current outbreak of hoaxes and rumours around the novel coronavirus Covid-19, understanding how certain hashtags, links or claims are travelling on Twitter could prove crucial to limiting the spread of damaging misinformation.
What is an API?
Many social media companies have restricted access to their APIs in recent years, complicating research into mis- and disinformation flowing across these platforms, but Twitter still offers various APIs that are open and free to the public.
An API, in essence, is software that allows different applications to talk to each other. In the case of Twitter, it allows users to communicate with and pull data from Twitter’s servers. Twitter’s APIs allow us to collect large samples of tweets based on hashtags, keywords and phrases, and usernames. The sample we collect contains different fields, including the hashtags in a tweet, user mentions, and account creation date, which offer many different avenues for investigation.
If you want to investigate what accounts are pumping out which hashtags or URLs, Twitter’s Standard Search API — different from its Streaming API — provides the easiest and cheapest (ie free) way of collecting a large body of tweets to do this kind of research.
Let’s say you wanted to investigate Covid-19 misinformation and how #medicalfreedom — a hashtag used by individuals lobbying against mandatory vaccinations in the US and Europe, some of whom also spread vaccine misinformation — may be a haven for falsehoods about the virus. How could you do this using Twitter’s Standard Search API?

Use this checklist to tap into Twitter’s Standard Search API and find stories. Akshata Rao/First Draft.
First things first
To do anything with Twitter’s API you need a recent version of Python (3.5 or higher) installed on your computer. If you don’t already have Python installed, you can download Anaconda, which is a free user-friendly Python environment that comes with a host of Python packages for scientific computing and data analysis. We also recommend you install a text editor for code, such as Sublime Text, which we will use in this tutorial.
In order to get the necessary tokens to access any of Twitter’s APIs, you need to set up a Twitter Developer account. Go to developer.twitter.com and then navigate to your name in the top-right of the screen. The drop-down menu will give you different options. Click on Apps. Once you are in Apps, click create Create an App. You will be asked a series of questions regarding what you intend to use the Twitter app for.
Over the last few years, Twitter has cracked down on what it sees as suspicious activity on the platform, so it’s likely they will also email a series of follow-up questions for further vetting.
Click on Apps on Twitter’s Developer site and then create an app in order to get the necessary tokens to access Twitter’s API. Screenshot by author.
If they are satisfied with your answers and don’t deem you suspicious, you will be granted an API key, an API secret key, an access token, and a secret access token.
Don’t expect this to be immediate. It will likely be a few days before you receive them but you will need these to access the API and pull data from Twitter. You can access these keys and tokens by clicking on the Details icon within the Apps section.

Once your app is approved click on Details to find your keys and tokens. Screenshot by author.
Once you have clicked on Details, navigate to “keys and tokens” where you will find the necessary credentials to access the API.
If it’s your first time accessing these tokens you may have the button Generate. Click this to generate the tokens.
You will need the keys and tokens in the Details section of your app to access the API. Screenshot by author.
Because we primarily use Python and Pandas for data analysis at First Draft, we chose the Python library Tweepy to access Twitter’s API. A library is basically an existing collection of functions and commands which mean you don’t have to write all your own code from scratch.
To download Tweepy on Mac, go to your terminal. You can access the terminal by holding command + spacebar, which will open Spotlight Search, and then searching terminal from within Spotlight Search. Inside Terminal, write pip install tweepy.
If you are using Windows, press Win + R, to open the Run function, type cmd and press Enter. Once inside the terminal, write pip install tweepy.
Getting the code and running it
Once you’ve received your tokens and keys from Twitter and installed Tweepy, you can begin pulling data through Twitter’s API. You can find the different data fields available through Twitter’s Standard Search API here.
First Draft has prepared a sample script that you can use. Use the link above to find the script in Github, copy and paste it in Sublime, and then add your token and keys in the relevant fields.
Add in your own tokens and keys in the script once you receive them from Twitter.
Add your own personal tokens and keys into your script or the one supplied by First Draft. You can either build on this script, adding in more data fields that you want to capture like mentions and the number of followers, or use it as is.
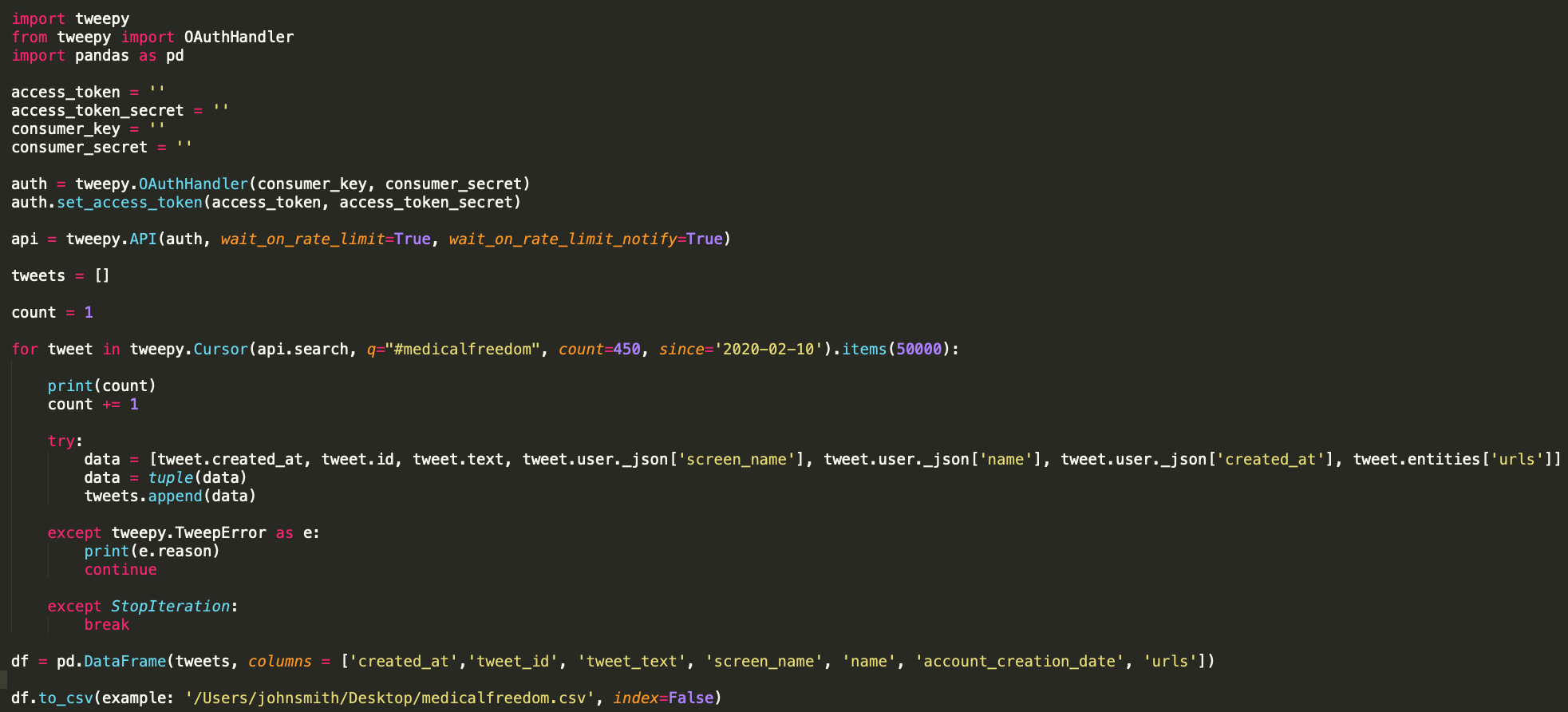
Here is the sample script that you can use to start pulling data from Twitter’s API.
In the query field, add whatever hashtag, keyword, key phrase, or handle you are looking for (for example, q=”#medicalfreedom”) and then add in the number of tweets you want to pull using the items.() feature (for example, items.(50000)).
You can set the number of items as high as you want. However, Twitter might not return the number you specified because there might not be that many tweets with the particular item you are looking for. If you are looking to capture trending Twitter data, Twitter displays the total number of tweets on the interface in the trends section. You can use this number to gauge the number you should input in items().
You can also set a custom date filter using the since and until parameters. It’s important to note that Twitter’s Standard Search API only goes back seven days. The count number refers to the rate limit, or the number of times that you can request data from the API in a certain time period. Leave this number at 450.
You can change these different parameters depending on the keywords, time frame, and number of Tweets you want to pull.
Before executing the script, add the path to the folder you want to store your data in as well as a name you want to give to the CSV file the data will be saved to.

Add the direction of the folder you want to save the CSV file in as well as a name for the CSV file.
In Sublime, you can run the script by navigating to Tools then clicking on Build in the dropdown menu.
After running the script, you should have a CSV file with 50,000 tweets in the folder you specified. If you don’t have that many tweets, it’s likely because there weren’t that many tweets published within the time frame you are looking at.
Analysing the data
Once you have your Tweets in a CSV, you can begin to analyse the data. We recommend that you have a clear idea of the questions you want to ask before you begin. Drafting these questions beforehand not only gets you thinking about whatever data fields you may want to pull from the API when building the script, but it also focuses your analysis, ensuring you don’t get sucked into a long and unproductive fishing expedition in the hope of finding something interesting in the data.
While there are any number of questions you can ask of your data, for this particular example, we are interested in answering the following:
- What are the top tweets with #medicalfreedom?
- Are there tweets related to coronavirus? Who is tweeting them?
- What accounts are tweeting #medicalfreedom most frequently?
- Within these top tweets are there any suspicious URLs, or URLs that contain misleading information around coronavirus?
Use whatever data analysis tools — Google Sheets, Excel, Pandas, R — you are most comfortable with to answer these questions. First Draft generally uses Pandas and Jupyter Notebooks for data analysis. Thankfully, the Anaconda environment we downloaded earlier includes Python, Pandas, Jupyter Notebooks and R. You can access Jupyter Notebooks by opening up the application and then clicking on the Launch button under the Jupyter Notebooks.

For your data analysis, you can access Jupyter Notebook for Python and RStudio for R within Anaconda.
In order to get the top ten most popular messages that includes #medicalfreedom you can do a basic value_counts in Pandas (see the code in figure below) on the tweet_text field. This will add up all the unique messages in the dataset.
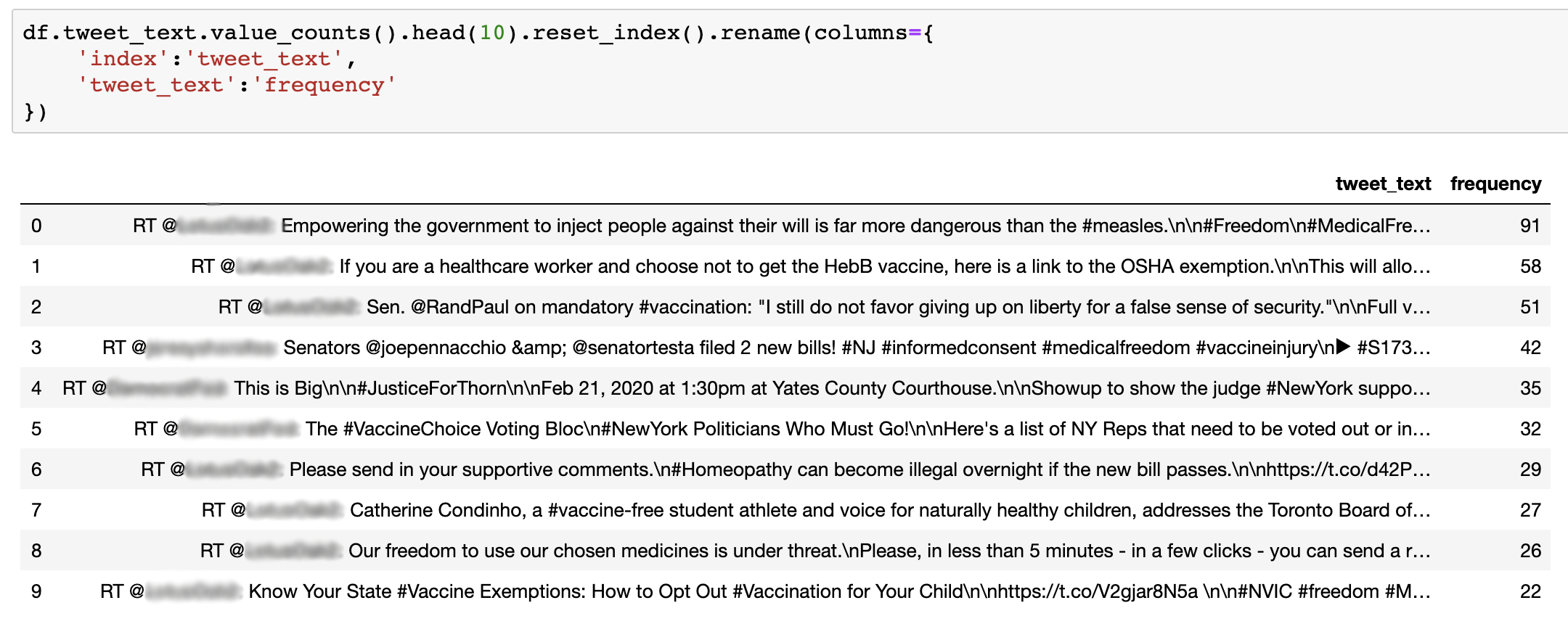
Doing a value counts (as seen in the code) returns the top ten most frequent messages in the dataset.
From this quick analysis, you can see that an account’s tweet (made anonymous here to protect the user’s privacy) was retweeted 91 times and is the most popular message in this dataset. The un-censored data reveals that many of the other top tweets also originated from that same user. So already, within this particular tweet sample, you can see that this account appears to be a key node in the network.
In order to isolate tweets related to Covid-19 in the dataset, you can search specifically for the word “coronavirus” in the text of the tweet, or tweet_text field. A bit of code (see below) will find the tweets and the users tweeting that content.
This is a good starting point for identifying and building lists of accounts that are tweeting suspicious or misleading content around Covid-19, especially as it relates to vaccines.
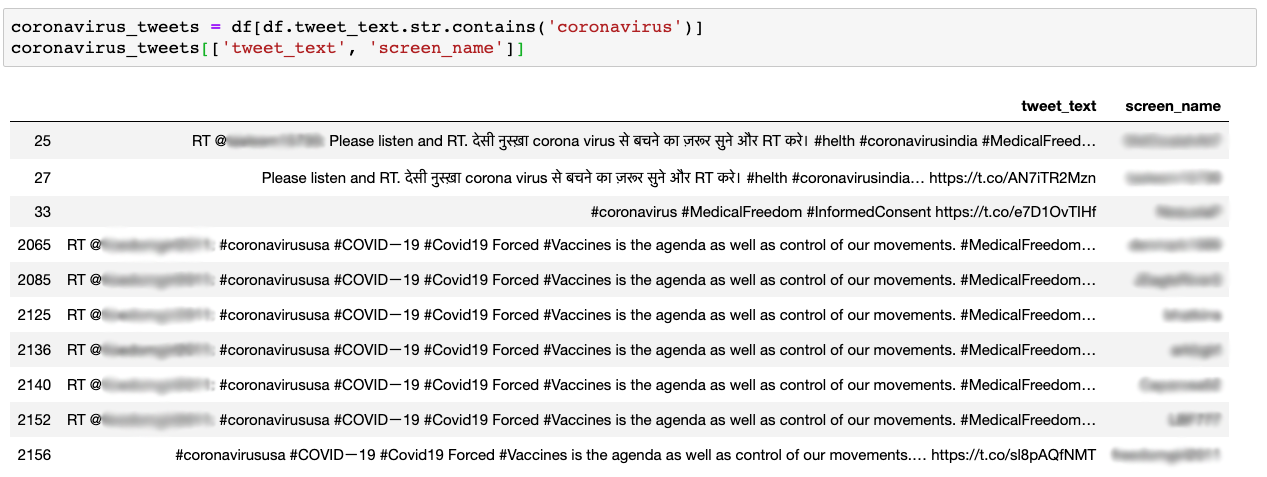
Tweets that include coronavirus in the dataset.
To see the most active accounts tweeting #medicalfreedom in this dataset, you can use a similar bit of code, which reveals the top ten accounts that have tweeted the most.
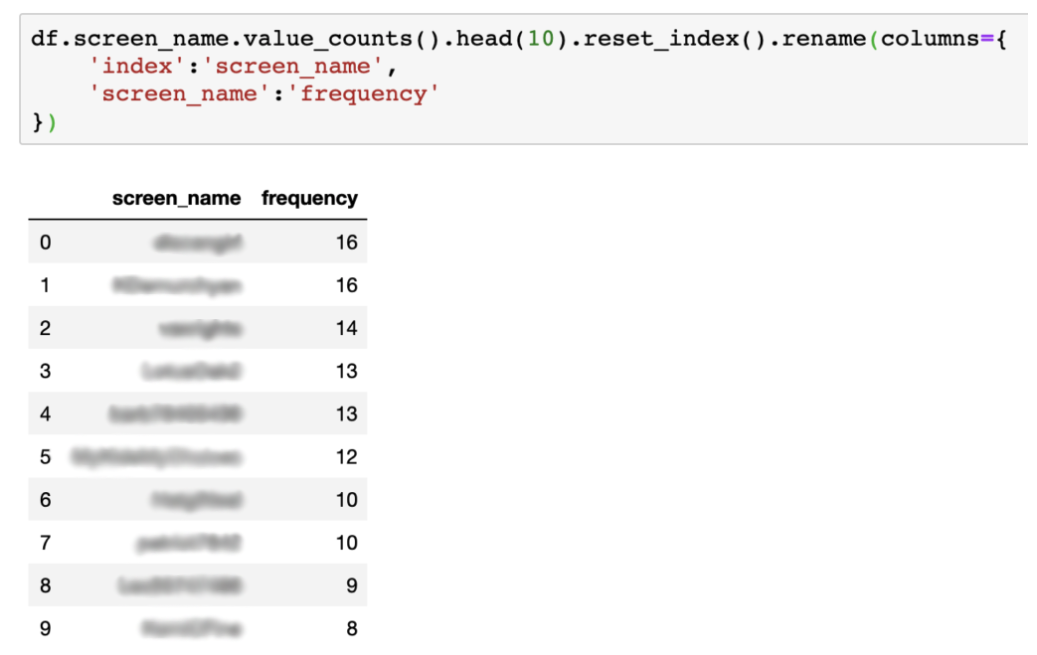
The ten accounts tweeting the most in this particular dataset.
A quick look at the Twitter feeds of these accounts reveals a number of questionable and highly emotive anti-vaccine tweets. Various feeds include links to a well-known anti-vaxxer website. And it’s worth mentioning that some of these accounts demonstrate various hallmarks of automation or bot-like activity. Such a finding, depending on the interests of your organisation or newsroom, may be worth further investigation.
Lastly, we can find the most popular urls shared in the dataset by unpacking the JSON file (see below) in the column urls. Here you can find the categories is url, expanded_url, and display_url.
The expanded_url is the expanded version of the URL, which is shortened within Twitter. This is the one we are interested in. To isolate the expanded_url from the JSON object, we have to unpack it.
We can do this by creating a simple function to extract the field, which is included in the script linked below.

The top URLs being shared within the #medicalfreedom sample.
Once, you have all the expanded_urls you can perform another value_counts function to get the most shared URLs in the sample.
You can find the code to extract the expanded_url field and sum the unique URLs get to this final step through this link.

A list of the top 10 most shared urls in the dataset.
The top URL is from the National Vaccine Information Center, which has been criticised as a leading source of vaccine misinformation and runs the blog The Vaccine Reaction.
Investigating some of the more popular URLs containing misinformation and the sites they come from via Google Analytics IDs and IP addresses is a good way to start mapping out possible networks of sites and people spreading vaccine misinformation online.
This is just the beginning
You now not only have a better idea of the key Twitter accounts using the hashtag #medicalfreedom in the last seven days, the top messages, and some popular URLs shared regarding this issue, but you also have the data and numbers to substantiate these claims.
Again, it’s important to note that this is merely a small sample of tweets and shouldn’t be understood to represent the entire community.
These are only a few of the many different questions that you may want to ask of Twitter data. For example, as part of an exploratory research phase, you may want to scrape all the different hashtags associated with #medicalfreedom to see what others are associated with this movement. Twitter’s Standard Search API is perfect for this.
The guidance provided here is just a snapshot of the approach to analysing Twitter data. You may also want to use network analysis tools such as Gephi and Python libraries like NetwokX to visualise different communities on Twitter sharing similar hashtags or mentioning the same accounts.
Nonetheless, with just a few simple questions and lines of code, we can identify some of the key accounts, posts and URLs associated with a hashtag, which you can use as a jumping-off point to further investigate and monitor certain communities and conversations.
Stay up to date with First Draft’s work by subscribing to our newsletter and follow us on Facebook and Twitter.


