
This article is available also in Deutsch, Español, Français and العربية
Another election, another round of reports that social media bots artificially boosted a candidate, and another case study underscoring the challenges of covering a new age of digital astroturfing.
For the UK general election, one notable attempt was the Telegraph’s article about a series of bots flooding Twitter with pro-Corbyn and anti-May messages. The story’s basic facts were vaguely right: There were a considerable number of high-frequency tweeters pushing pro-Corbyn messages in the final weeks before Election Day. But the piece fell short of providing hard proof of scale or intention.
The possibility of robots inflating the size of one candidate’s apparent support — let alone spreading misinformation — is worth reporting. But proper analyses of these networks demand skills and thinking that are totally new to social scientists, let alone journalists.
How can we even begin to think about verifying things like bot campaigns? What questions might we ask if we’re looking for pro-Corbyn bots? Here are a few thoughts:
How do we define ‘bots’?
Most of the work that’s been done in bot detection has focused on assembling scores from a set of characteristics, like followers, friends and account ages. While features like these can be telling, the index approach can be too rigid in its assumption that all bots look the same. My work, by contrast, has shown me that every group of bots is distinctive, having different characteristics that label them as fake.
But it’s also not the case that all automated activity comes from accounts that are wholly inhuman. Besides accounts operated exclusively by software, there are reported cases of ‘cyborg’ accounts jointly operated by people, and legitimate accounts lended for use in automated campaigns. These accounts look partly normal, only displaying unnatural behavior narrowly or sporadically.
Bot or not, one property of automated accounts engaged in campaigns is more immutable, because it is directly tied to their value and costly to avoid: They post a lot. Creating a large volume of chatter that advances your agenda is the goal of an automated social media campaign. But the only two ways of doing that are to (1) to have a few accounts post a lot or (2) have a lot of accounts post a little. The latter is much more expensive. Thus, high-frequency posting is generally a good place to start in the search for suspect accounts.
To this idea, the Oxford Internet Institute has put forward a definition for a high-frequency tweeter : an account that tweets more than 50 times per day on average. Even this standard isn’t perfect, as it sometimes flags the more tweet-prolific among journalists, for example. Other researchers prefer stricter cutoffs. But Oxford’s definition is generally right, workable and credible.
How many high-frequency tweeters engaged with Corbyn’s and May’s accounts?
When searching for networks of automated accounts, one requires data on activity, users, followers and friends. In the case of Twitter, that means making calls to several of Twitter’s APIs, or application programming interfaces (i.e., systems for making programmatic web requests for data).
There are two APIs from which one can retrieve tweets about a topic: the Search API and the Streaming API. Both take a search term as input and return tweets that have that term in their text. For example, by searching on the handles ‘@jeremycorbyn’ and ‘@theresa_may’, we can collect a sample of tweets that mentioned each account, including retweets.
Each API has its advantages and disadvantages. The Search API, for instance, returns an incomplete sample of tweets that may under represent accounts that are “spammy.” However, it is the only API that allows retrieval of tweets that have already been posted, so that’ s what I use here.
I generated two random samples of 5,000 accounts that mentioned either Corbyn’s or May’s Twitter account between May 25 and June 5.* Then I pulled the timeline of each account using Twitter’s Timeline API and calculated its average daily tweet frequency. (Technically, one could calculate a rough frequency estimate by dividing an account’s status total by the number of days since its creation. However, this method risks false negatives in cases where accounts were inactive for a long period of time or had its tweets deleted.)
Almost 7 percent of Corbyn’s mentioners met Oxford’s definition of a high-frequency tweeter. But, due to their productivity, these accounts posted more than 19 percent of the sample’s mentions of Corbyn. In other words, a proportionally small group of high-frequency tweeters posted almost one out of every five of the sampled Corbyn mentions and retweets.
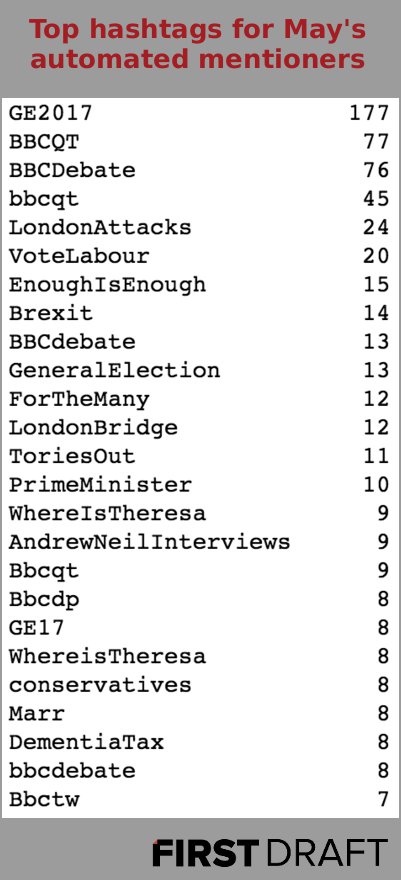 But what about May? Perhaps surprisingly, the Prime Minister’s mentioners had a much larger share (more than 10 percent) of accounts fitting Oxford’s high-frequency standard. Yet, despite constituting more of her mentioners, high-frequency tweeters posted only 22 percent of May’s mentions and retweets—just slightly more than what Corbyn’s automated mentioners produced.
But what about May? Perhaps surprisingly, the Prime Minister’s mentioners had a much larger share (more than 10 percent) of accounts fitting Oxford’s high-frequency standard. Yet, despite constituting more of her mentioners, high-frequency tweeters posted only 22 percent of May’s mentions and retweets—just slightly more than what Corbyn’s automated mentioners produced.
These figures are particularly notable given the Search API’s potential bias against spam accounts and the fact that a previous study from Oxford found lower levels of high-frequency activity using the Streaming API.
What were the accounts tweeting?
Automated activity isn’t that incriminating on its own. A recent study from USC and Indiana University estimated that between 9 and 15 percent of active Twitter accounts are automated, tweeting everything from news to postmodern poetry. Knowing this, it’s necessary to look at whether our potentially computer-aided tweets were relevant to election and promoted one candidate over the other.
Looking again at each account’s timeline, an average of 79 and 76 percent of tweets from Corbyn and May’s automated mentioners, respectively, were retweets rather than original content. The rest of the automated mentioners’ tweets were largely made up of normal-looking replies.
The top 25 retweets from Corbyn’s automated mentioners in the search data were all kind to the Labour leader, and 18 of were retweets of Corbyn himself. However, the top retweets for May’s mentioners were all critical of the Prime Minister and also included several retweets of Corbyn, who made a habit of including May’s Twitter handle in his tweets. But even after discounting all of Corbyn’s retweets, only one of the top tweets was in support of May.
Top retweet of Corbyn high-frequency tweeters:
So some Conservative came to visit my mum while I was FaceTiming her. You’re gonna wanna watch this. @jeremycorbyn pic.twitter.com/5IMB9BRqQJ
— tom (@tomosgjames) June 2, 2017
Top retweet of May high-frequency tweeters:
.@theresa_may Why are you missing from this statement? You can’t stand up for Britain because you won’t stand up to Trump. Weak leadership. https://t.co/e26AjMugMY
— Ed Miliband (@Ed_Miliband) June 1, 2017
This pro-Corbyn pattern is mirrored in the top hashtags used by both sets of high-frequency tweeters. For those among Corbyn’s mentioners, each of the top 25 hashtags was either pro-Labour, neutral or unrelated to the election. By contrast, the preferred hashtags of May’s mentioners included #VoteLabour, #ForTheMany and #ToriesOut.
None of this is to say that there weren’t bots working in May’s favor. For example, Corbyn’s most talkative repliers were May proponents. But a left-leaning bias among the high-frequency tweeters is evident.
Is there any evidence of a network?
Given that many of the automated accounts seem to have the same political skew, it’s worth asking if there’s overlap between the two samples.
Indeed, half of Corbyn’s automated mentioners also mentioned May at least once, and around 62 percent of the May’s automated mentioners also mentioned Corbyn. That’s not necessarily surprising, due to how often Corbyn mentioned May. However, there are other factors that suggest the accounts may be connected. Another set of calls to another API—the Friend API—yields lists of account IDs representing each account’s friends. Armed with these IDs, one can create tables describing the accounts’ relationships.
More than 55 percent of the automated mentioners were followed by another automated mentioner, and almost 24 percent of the mentioners’ friends (i.e., the accounts they follow) were shared by at least two of the mentioners. (Note: These numbers would likely get larger as the sample size increased.)
It’s not clear that the network I found is the same as the one reported in the Telegraph. Only 2 percent of the high-frequency tweeters had names matching the pattern described in the Telegraph article, a name followed by eight digits. However, the lack of such accounts may be due in part to the Search API’s bias against certain accounts.
Conclusion
To a concerning degree, automated Twitter accounts pushed pro-Corbyn and anti-May messages in the last part of the election. Moreover, it appears that at least some of these accounts may belong to the same network.
However, there is nothing in the findings I’ve offered here that links the accounts to the Labour campaign or any other group. It’s even debatable that these accounts were explicitly mobilized to boost Corbyn: Bots are known to arbitrarily engage with content in an attempt to appear more natural. Much of Twitter is political, so we would expect automated accounts to engage with politics to some extent. But, in any case, the influence of these accounts on the election conversation is the same.
Reporting on digital astroturfing is important work. Bots cannot vote, but perceived support for a candidate is a critical influence on those of us who do. Journalists continue to take cues from social media like Twitter, and, with newsrooms continuing to shrink and reporters’ time becoming ever more valuable, that doesn’t look to change.
We’ve begun thinking about how to search for automation on social media, but how can we prepare journalists to do this work? Perhaps news organizations should partner with universities to send graduate students in the computational sciences to join newsrooms during elections. But, of course, automation occurs outside of elections, too. The best answer may be to establish partnerships between researchers, developers and data journalists to develop easy-to-use tools and organize training events.
Whatever the solution, we have to find it. We can’t afford to be outrun by bots.
* This analysis is based on almost 460,000 tweets retrieved twarc calls to the Twitter Search API. All Corbyn mentions were made between May 25 and June 4, and all May mentions were made between May 31 and June 5. Smaller random samples of accounts were necessary, because additional calls to the Twitter Timeline API to determine accounts’ tweet rates were relied upon.
Facebook and Google News Lab supported First Draft and Full Fact to work with major newsrooms to address rumours and misinformation spreading online during the UK general election.
This is the fourth in a series of blog posts about the Full Fact-First Draft UK Election project.
1. UK election first post: what we learned working with Full Fact
2. How we fact-checked the UK Election in real time
3. The types of misinformation we saw during the UK election